Most of the time they’re just there to make you _think_ that you shouldn’t be opening the box. In the US the Magnusen–Moss Warranty Act of 1977 explicitly prohibits companies from voiding any warranty merely because the owner opened up the device, repaired it, or had it repaired.
Crime had already been falling consistently for several hundred years throughout Europe when the first gun-licensing and gun-control laws were being passed in the Wiemar Republic. You don’t need control over weapons to reduce crime, you just reduce crime.
Incidentally, a few years later a certain political party got their candidate elected Chancellor. He more or less immediately ordered the police to use the gun-licensing records to identify Jews who owned guns and had them arrested. It’s actually pretty hilarious, in a very dark way, to read some of the arrest reports. When Jews were ordered to surrender their weapons to the police, many of them brought the weapons to a police station as instructed. They politely stood in line while the officer at the desk wrote out arrest warrants for them one after the other. The crime? Carrying an unlicensed weapon. The location? The police station in such-and-such precinct. The witness? The officer at the desk. The prisoner? Turned over to the SS.
Err, be careful. You made these improvements sequentially, not independently. Each one halved your costs and might still have done exactly that if done in the opposite order.
Look closer. How could his 20kW rooftop solar electricity have halved his initial monthly costs, when >3/4 of those costs were for propane heating fuel? (Vs. <1/4 for electricity.)
Sadly people don’t always do what’s best. We sometimes do what other people are doing on the theory that maybe someone else has thought it through and already decided that it _is_ the best thing to do. It’s not perfect, but then heuristics rarely are. But it’s cheap to implement.
Seriously, how on earth are you coming up with this? Time and again they debunk those silly claims but people just keep bringing this up on and on. Is it some sort of conspiracy theory?
It could be a conspiracy on the part of Canonical, sure. People have hidden motives all the time. Sometimes you have to deduce their motives from their actions, while ignoring their words.
I don't think there’s any serious evidence of it being true though. All we can see right now is that there are a surprising number of MIT-licensed packages replacing GPL-licensed packages. It could be a coincidence.
I get it that the distinction is real but nobody using the machine cares at this point. It must not happen and if disabling swap removes it then people will disable swap.
This is not really true of most SSDs. When Linux is really thrashing the swap it’ll be essentially unusable unless the disk is _really_ fast. Fast enough SSDs are available though. Note that when it’s really thrashing the swap the workload is 100% random 4KB reads and writes in equal quantities. Many SSDs have high read speeds and high write speeds but have much worse performance under mixed workloads.
I once used an Intel Optane drive as swap for a job that needed hundreds of gigabytes of ram (in a computer that maxed out at 64 gigs). The latency was so low that even while the task was running the machine was almost perfectly usable; in fact I could almost watch videos without dropping frames at the same time.
Do you know how the le9 patch compares to mg_lru? The latter applies to all memory, not just files as far as I can tell. The former might still be useful in preventing eager OOM while still keeping executable file-backed pages in memory?
le9 is a 'simple' method to keep the fixed amount of the page cache. It works exceptionally well for what it is, but it requires manual tuning of the amount of cache in MB.
MGLRU is basically a smarter version of already existing eviction algorithm, with evicts (or keeps) both page cache and anon pages, and combined with min_ttl_ms it tries to keep current active page cache for a specified amount of time. It still takes into account swappiness and does not operate on a fixed amount of page cache, unlike le9.
Both are effective in trashing prevention, both are different. MGLRU, especially with higher min_ttl_ms, could cause OOM killer more frequently than you'd like it to be called. I find le9 more effective for desktop use on old low-end machines, but that's only because it just keeps the (large/er amounts of) page cache. It's not very preferable for embedded systems for example.
That may be the intention, but you shouldn’t rely on it. In practice the average IO size is, or at least was, almost always 4KB.
Here’s a screenshot from atop while the task was running: <https://db48x.net/temp/Screenshot%20from%202019-11-19%2023-4...>. Note the number of page faults, the swin and swout (swap in and swap out) numbers, and the disk activity on nvme0n1. Swap in is 150k, and the number of disk reads was 116k with an average size of 6KB. Swap out was 150k with 150k disk writes of 4KB. It’s also reading from sdh at a fair clip (though not as fast as I wanted!)
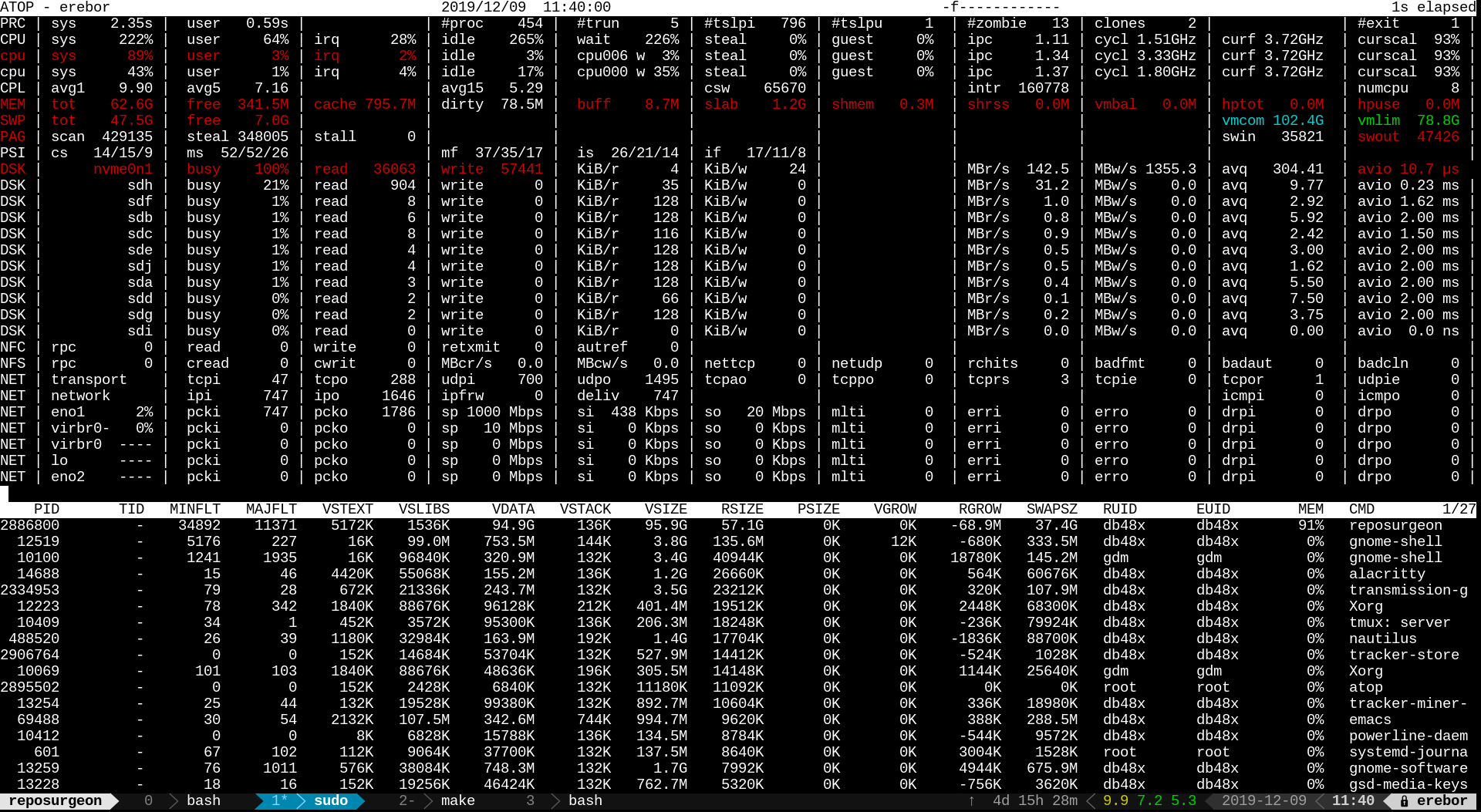
<https://db48x.net/temp/Screenshot%20from%202019-12-09%2011-4...> is interesting because it actually shows 24KB average write size. But notice that swout is 47k but there were actually 57k writes. That’s because the program I was testing had to write data out to disk to be useful, and I had it going to a different partition on the same nvme disk. Notice the high queue depth; this was a very large serial write. The swap activity was still all 4KB random IO.
That's surprising. Do you know what your application memory access pattern is like, is it really this random and the single page io is working along its grain, or is the page clustering, io readahead etc just MIA?
I didn’t delve very deep into it, but the program was written in Go. At this point in the lifecycle of the program we had optimized it quite a bit, removing all the inefficiencies that we could. It was now spending around two thirds of its cpu cycles on garbage collection. It had this ridiculously large heap that was still growing, but hardly any of it was actually garbage.
I rewrote a slice of the program in Rust with quite promising results, but by that time there wasn’t really any demand left. You see, one of the many uses of Reposurgeon <http://www.catb.org/esr/reposurgeon/> is to convert SVN repositories into Git repositories. These performance results were taken while reposurgeon was running on a dump of the GCC source code repository. At the time this was the single largest open source SVN repository left in the world with 287k commits. Now that it’s been converted to a Git repository it’s unlikely that future Reposurgeon users will have the same problem.
Also, someone pointed out that MG-LRU <https://docs.kernel.org/admin-guide/mm/multigen_lru.html> might help by increasing the block size of the reads and writes. It was introduced a year or more after I took these screenshots, so I can’t easily verify that.
He explained that. His inexpensive oscilloscope _can_ trigger from the second channel, but only at one billion samples per second. Where’s the fun in that?
{kind=link}
{kind=link}
reply