"This will be unlocked shortly. Per my earlier post, drastic & immediate action was necessary due to EXTREME levels of data scraping.
Almost every company doing AI, from startups to some of the biggest corporations on Earth, was scraping vast amounts of data.
It is rather galling to have to bring large numbers of servers online on an emergency basis just to facilitate some AI startup’s outrageous valuation."
I have a bridge to sell anyone who believes this is true. AI companies have been a boon to businesses that want to lock down user data and now have an excuse. It may be true to the extent that Musk is legitimately angry that Twitter isn't getting a piece of that AI VC money (I'm sure he is). But:
A) Twitter would probably move in this direction even if AI companies didn't exist, this is an excuse. Nothing about Musk's Twitter has indicated that he cares about Open data access or anonymous access to the site, and this follows a general trend of closing down the platform to non-monetizable users. Musk has abundantly shown in the past that he would prefer everyone browsing Twitter be logged into an account.
B) "it's temporary" -- how? You don't have a way to stop this other than forcing login. That situation is not going to change next week. To call this "temporary emergency measures" is so funny; there is no engineering solution for this and you're not going to be able to successfully sue companies for scraping Twitter. Put a captcha in front of it? Sure, let me know how that goes.
You going to wait and see if the AI market collapses in the next month?
If this does turn out to be temporary, it'll only be because of migrations off of Twitter and because of user criticism, because Musk is impulsive and bends easily under pressure. But nothing about the situation Musk is complaining about is going to change next week.
> there is no engineering solution for this and you're not going to be able to successfully sue companies for scraping Twitter
There absolutely is, if you try instead of whining on internet. People at Vercel have already developed new anti-bot + fingerprinting + rate limiting techniques which look quite promising. I dare say within a year, new tools will be powerful enough to do this easily.
> I dare say within a year, new tools will be powerful enough to do this easily.
I see where you're coming from, but if Twitter is in a position where it can't roll out those protections right now, given its current head counts, etc... it's not going to be in a position where it can roll out those protections next week. Probably not next month.
So it's less that no one could block companies from scraping Twitter (although anti-scraping mechanisms are probably always going to be a cat-and-mouse game, so I'm not sure that there is ever going to be a perfect easy solution). It's more that if Twitter can't do it right now, nothing is going to magically change any time soon about the situation it has found itself in. And waiting a year (even waiting 6 months) for tools to become available before rolling back this rate limiting would be incredibly self-destructive for Twitter.
The way I see it, they're basically guaranteeing that they will need to roll back these changes before they have a solution to whatever specific problem or irritation Musk is fixated on. They're not going to gain additional engineering capabilities in the next week. And how long does Musk plan to leave rate-limiting in place? A social media site where people can't look at content is just broken.
> Nothing about Musk's Twitter has indicated that he cares about Open data access or anonymous access to the site
Not so, he tasked George Hotz with getting rid of that horrible popup which prevented you from scrolling down much if you weren't logged in, which was added soon before he bought Twitter. When that was removed I rejoiced. But now Twitter's gone 100x in the opposite direction.
I don't know; was that Musk's idea, or was that Hotz's idea? I vaguely think this was a change that Hotz wanted that Musk went along with.
To be fair, Musk will regularly pay lip-service to the idea of Open communication. I guess that's not literally nothing, but most large site policies have been in the direction of locking down content.
If there ever was a version of Musk that cared about Open access, it's been a while since that version of him saw the light of day. It's very consistent with his overall behavior to believe that he views Twitter content as being primarily his property rather than a community resource, and that he thinks that scrapers/AI companies/researchers are literally stealing from him if they derive any value at all from data that Twitter hosts.
Elon has a good point there. Much of the current AI hotness is predicated on stealing peoples content and exploiting the infrastructure that other people have built. I don’t think it’s acceptable.
The licenses, compensation models, law, technical solutions, attribution, security and privacy all need time to catch up. Regulation has a role to play as its a bit of a free for all right now.
The irony of Elon mentioning “outrageous valuations” though!
Why would an AI company start scraping twitter html, instead of using an already existing archive? Something similar to archive.org could earn money from that. If all you want is the content, there's no reason to suck it through a straw.
I'd expect those that require real time data, such as stock market bots or sentiment data providers, to scrape twitter (if they don't provide the data by other means, for example the "firehose", which is another great way to earn money).
None of this makes much sense.
Also, it's much more complicated than it seems. The web works because the data is public. You cannot think of it as "my data". (Especially not twitter, since it is really their users'!) Twitter is not higher quality data than any other web page.
If we accept that thinking, every home page would require a login to see that specific company's phone number of opening hours. Those pieces of data are also valuable, in the right circumstances! And then the web would either not exist or the account system required would be so wide spread that accounts would carry no value and the system would become useless.
> Why would an AI company start scraping twitter html, instead of using an already existing archive?
I can think of a few possible reasons. They might want more up-to-date info, or they might have no real developers and the scraper was created by a business guru who prompted ChatGPT and didn't understand the code that came out.
Given what else Musk has asserted about Twitter, and how often former or current Twitter devs have contradicted him, it may not even be what Musk said.
> Twitter is not higher quality data than any other web page
Eh, depends how much you can infer from retweet, favourites, etc.
Won't be the only such site, but it's probably better training data than blog posts are these days.
But yeah, I absolutely agree that Twitter doing this caused a lot of damage to any orgs, corporate or government, which wanted to be public, anything from restaurants announcing special offers to governments issuing hurricane warnings. Twitter isn't big enough to assume everyone has an account, like Facebook is.
If there was more value in requiring login than there is in having this public and easily accessible, it would be behind a login form. The current internet has 99% of the time nothing to do with values someone imagined in the 80s
Value to whom? Twitter is more valuable to its users, to journalists who embed tweets in stories, and to web users at large who follow links and search results if it does not require a login to view posts.
Of course, none of those people own Twitter, and it may well be more valuable to its owners if it does require a login.
What you describe is the Facebook business model. Which seems to be a valid model, but twitter was not built around it and such a pivot would break all business moats around the company.
There was no web in the 80s so not sure what values you refer to, or how they are relevant to today's businesses.
If every AI company pointed their scrapers to archive.org, that site would go down immediately as well.
This is just kicking the can down the road.
We have a major structural problem now. We want data to be free and machine readable, but no startup (and even a giant like Twitter) can afford the server cost to withstand all those machines.
> Elon has a good point there. Much of the current AI hotness is predicated on stealing peoples content and exploiting the infrastructure that other people have built. I don’t think it’s acceptable.
But then so is Twitter. They don’t produce any content whatsoever. The data they are having a fit about is not theirs, it’s been volunteered by the users. It’s the same line Reddit is pushing, and it’s bullshit. AI companies scraping the web is no more unethical than Google doing it.
Well, one thing is people going there and putting their data on a platform. That’s their choice.
Taking/scrapping/stealing that data out of said platform for the benefit of your over-hyped “disruptive” startup - and implying that others should give you all for free - is the issue.
That’s not the point. Twitter has a non-exclusive license to distribute the content; it’s not the owner of the data regardless of the high horse Musk feels like riding today.
Please don't throw around the word "stealing" so loosely.
Scraping data from a public website is not "stealing". It might be a violation of the terms of service, but then you have the whole issue of click-through (formerly shrink-wrap) licenses and contracts of adhesion.
If someone isn't vetting you and potentially signing you to a more meaningful contract before giving you access, for free, to data, then using that data for any purpose whatsoever (except republishing it or derived works, which might, depending on the nature of the data or the derived works, be a violation of someone's copyright) is so far from "stealing" that using that word is wrong, and I suspect intentionally inflammatory.
That's why Elon limited access, rather than going to the police to file charges for theft, or suing over copyright violation or breach of contract. Not to say he absolutely couldn't do the latter, but it's hardly a clear win.
1. Users or one might say content creators don't own their data. Not just do those platform owners make a lot of money with the content (which they have a license to, as per site ToS) but then you have third parties scraping it now for commercial products. Using the data to train models that are then sold back to some of the same social media users who produced the content for free in the first place wasn't a thing until very recently, it used to be a select few doing machine learning research in the past. The laws are lacking behind the tech development and regular internet users are being exploited because of it.
2. It absolutely is stealing in some cases, and even worse. For example when they scrape it for content which they then use to train their bots to impersonate humans. Or on Twitter, there's a very common type of bot that steals content from young attractive female social media users in China, auto-translated to English, to pose as them. If you're in finance and crypto circles they're swarming with these accounts (guess the scammers know their targets).
3. In general this is only going to get worse from here on. LLM are getting better and better. On sites like Twitter you already have no idea if you're interacting with a human or not. But these "AI" can not actually think for themselves, they can only emulate, they can copy other humans. At least so far. So for the sake of making progress and ensuring we can still have intelligent discussions and find novel ideas online, it's imperative to have a way to keep the machines out. Social media must become sybil resistant or it dies in a vicious circle of self-referencing bots ever parroting the same old talking points, or variations thereof. We urgently need human ID!
You may wish AI didn't exist, but it does. There's no putting the genie back in the bottle. We can still go after people who commit crimes using AI. Perhaps one day AGI will be possible and we will want to have discussions and share ideas with it just as do now with each other.
Governments, researchers, and all kinds of third parties have already been scraping every publicly available bit of data possible. There may be an increase now, but it's nothing new. It won't be the end of the society or the end of the internet anymore than AI will.
We may be using different definitions of 'intelligence'. To me there is no AI that currently exists but I'm aware the companies market it as such of course.
>have already been scraping every publicly available bit of data possible
Data scraping is limited by economics just like anything else in the world. Storage costs money, someone has to pay for it. Researchers do not have unlimited funds. Some select few governments like the US may have most of the publicly accessible web archived. Keep in mind it's dynamic and requires massive data infrastructure to pull this off, there's tons of new data coming in daily. Private startups getting in on the action in a big way is a relatively new phenomenon, this used to be limited to enterprises with a specific purpose. Now everyone and their 4chan cousin are experimenting with their own deep learning models.
Bots aren't people and can't read nor consent. They just consume.
Any page which can be served without first displaying a ToC or other terms which explicitly prohibit access is not protected by a ToC or other license from scraping, as they can be considered a Point of First Contact in each case, as the bot has selected each link from a simple aggregation of all links it encounters (each interaction being "new" in essence).
Now it could be argued that ignoring robots.txt is an explicit contravention of norms and standards which could be viewed as a violation of an implicit licence, but there is no law requiring adherence to robots.txt and thus no mandate that a program even look for it iiuc.
Bots aren’t people and can’t consent, sure - but they are tools that are wielded or deployed by people who absolutely can consent (setting aside whether click-wrap terms are enforceable or not). If I throw a brick through a window, it’s me in the shit, not the brick.
If I have an open door to my business and someone's automated robot walks in the door to see what's available, how is that different?
Even more applicable, this is like saying that a person walking down the street can't have a camera and take a picture of the front of the building....
Because the page you land on when entering a url is in fact little different than a store front, with the associated signage and access points defining how a person or automated device may interact with that business.
If you want to have it different then you have to actually put everything behind a locked door with no window, right?
This could easily be solved by making the unauthenticated access hard for machines to consume, like introducing delays or some kind of captcha or even just proof of work (reverse some hash). While the authenticated get all the snappiness they want.
I'm strictly anti account, so he just lost me as audience. The next walled garden after Facebook and Instagram that won't ever see me again.
It already was semi-hard to machine-read, that is the reason I use Nitter for doing my small-scale continuous scraping of twitter which is now temporarily broken. Nitter is tons easier to parse as it's not reliant on JS, etc, and simpler to create screenshots of with headless chrome.
However if you mean implementing some even worse obfuscation (kind of like FB putting parts of words in different divs etc) that is not really compatible with the situation that this needed to be done as more of a temporary emergency measure. And PoW doesn't sound reasonable because it sets mobile devices against the scraper's servers. If all of this was just so easy, scraping would be dead. Good that it isn't.
> And PoW doesn't sound reasonable because it sets mobile devices against the scraper's servers.
Scraper servers and mobile devices have different access patterns though. I I'm reading tweets then I'm fine waiting 1 second for a tweet to load. Page load times for this kind of bloated stuff are super slow anyway, meanwhile my mobile could spend a second or two on some PoW. But if you want to large-scale scrape, you suddenly have to pay for 1bn CPU seconds. And this PoW could even keep continuously increasing per IP. 0.1% with every tweet. Not noticeablr for the casual surfer sitting on the toilet, neck-breaking for scrapers.
> If all of this was just so easy, scraping would be dead. Good that it isn't.
Small-scale scraping could still be provided through API access or just a login.
The reason they are not doing the "easy" thing is that they don't see a need (yet, perhaps). Just get an account, they'd say, and they are right. It works for Instagram too, except for some weirdos who nobody really cares about.
Of course the scraper would have to pay too. But it makes for a race between how much they are willing to pay, versus how much worse the experience gets for real users. And for successful mobile apps, reducing average load even during active use is important (example: idle games that don't want to make your phone a drying iron, companies invest in custom engines and make all kinds of compromises to avoid this). And burst-allowing rate limiting is something I'm quite sure was already in place, especially with prejudice towards datacenter/VPN IP's. But similarly to how it is with search engine scraping, professional scrapers already have costly workarounds for these.
>The reason they are not doing the "easy" thing is that they don't see a need (yet, perhaps).
This argument just doesn't make any sense. Twitter notes that this is hurting them. Previews in chat apps, just clicking links in non-loggedin contexts is are broken. I feel like you just predict that this will turn out to be more accepted in the near future and become more a more permanent decision, which you don't like.
HTTP Status Code 429 exists for this very purpose. While I sympathise with the idea that services need to protect their content from scraping to power AIs, I can't help but feel its a convenient excuse for these companies to re-implement archaic philosophies about online services. i.e. Killing off 3rd party apps and walling their garden higher, both feel very boomer in their retreat from the openness of the internet that seemed to be en vogue prior to smartphones. Perhaps this is just the transition from engineers building services to business, legal and finance trying to force the profit.
Correct me if I'm wrong, but surely throttling scrapers (at least ones that are not nefarious in their habits) is a problem that can be mitigated server-side, so I find it somewhat galling that its the excuse.
No matter what you do, this will cost server infra. That's Musk's argument for disabling access altogether.
Therefore it would make sense to have a solution which burdens the client disproportionately in relation to the server. A burden so low for the casual user that it's negligible but in aggregate, at scale, would break things. Which is what he wants.
Looks to me like both reddit and twitter are using the wedge to rather increase the height of the wall of their gardens and kill 3rd party development as opposed to genuinely trying to license bulk-users appropriately.
You're gonna need to license api keys so you're already identifying consumers and there's your infra which you need anyway. At which point you can throttle anyone obviously abusing whatever free/open-source tier offering you give out as standard.
Unless the captcha is annoying enough to a significant degrees, I doubt that it would work. With all the money in the bucket, scrapers can just hire a captcha farm to get pass the captcha with help from a real human.
Also a side note: distributed Web crawler is not unheard of these days, as well as residential IP proxies. Meaning the effectiveness of Proof of Work model maybe also limited.
Many online services (including Twitter) do employ some kind of IP address scoring system as part of their anti-scraping effort.
These systems tend to treat residential proxies as normal users, and puts less restrictions on them. On the other hand, if the IP address belongs to some (untrusted) IDCs, then the system will enable more annoying restrictions (say rate limits etc) against it, making scraping less efficient.
The other option would be to front caches through ISPs and the like.
This works far better when the items requested are small in number but large in volume (that is: a large number of requests against a small set of origin resources). When dealing with widespread and deep scraping, other strategies might be necessary, but these aren't impossible to envision.
Specifically permitted scraping interfaces or APIs for large-volume data access would be another option.
Of course, there's the associated issue that data aggregation itself conveys insights and power, and there might be concerns amongst those who think they're providing incidental and low-volume access to records discovering that there's a wholesale trade occurring in the background (whether that's remunerated or free of charge).
Elon is making a point and a reminder for everyone that what you share on social nets like Twitter is basically not owned by you, but the service.
Actually I’m surprised this took so long to do, and in the light of doing so shows that perhaps Twitter was sold for its existing content rather than existing or active user base.
AI startups training data covers content going back years. DALLE for example was trained on hundreds of year old paintings alongside more modern works.
Age may be included as part of the training but they generally want to suck up as much data as possible.
You consented to their being able to delete it when you agreed to their terms of service. It’s like if you hire someone to clean your home. Mostly they’re tidying up and dealing with dirt and dust, but if they see what looks like a used napkin lying somewhere, they will probably throw it out without first asking if you still want it - without that being stealing and without ever owning it themselves.
It may seem weird weird to compare useful content to a used napkin, but hey, successful business founder stereotypes do quite often involve have an idea written on a napkin…
I didn't consent to anything, I don't have a Twitter account. I'm talking about people who do. And they often mistakenly think their content will stay on Twitter forever, so they don't need to back it up.
Fair enough. By “you consented … when you agreed”, I really meant “one consents … when one agrees”, as is common in informal English.
Yes, it’s a mistake to rely on social media content remaining up forever, agreed. That’s separate from ownership. Backups are important even for data on a hard drive you physically own, since hard drives can fail or be damaged or lost.
How do you define stealing? Is the AI data obtained from accessing private data? Data that users did not make publicly available but kept to themselves on their own devices?
I can't really agree. We've already had rulings about data scraping and I don't see the difference here. Just that a lot of people do it now?
Also, Twitter is a public platform. Twitter didn't generate comments, and people posting on a public account are indirectly subject to public viewing. Not much different from being indirectly recorded in a public park
If I visit Twitter to work out how to sort some JavaScript issue, and that makes my company $X, am I stealing content, or am I just using the platform?
There's one major player making money off of other peoples content here, and that's Twitter. Why are they ok doing that, but not anyone else?
Used responsibly, of course it is. A developer is able to ingest current language used in exchanges about current topics, as well as cite prominent sources that are still using the platform.
It's not like Twitter is compensating tweet authors either. For using art the debate is still opened in my opinion even if I'm personally not in favor of it but I don't see how those platforms built on user made content (even more of a clear cut than AI) can have a say on this
People are happy to put their content on social networks. Maybe they get some value in return such as sales, exposure, signalling or simple enjoyment.
Many people who aren’t that privacy conscious would however object to lots of companies, big and small, sucking their content into their databases for their own uses, then republishing after it’s passed through a few AI models.
>People are happy to put their content on social networks.
Do they have a choice? A handful of corporations have captured all the network effects. If you need to reach an audience to do your job or find your "friends", what other choice do you have but to give your data to them?
>If your friends are close enough do you need a big corporate network to share content/thoughts? If they aren't close why do you care?
I don't personally have this problem, but my observation is that most social relationships are somewhere in between closest friends and don't care.
My own concern is more about participating in professional, neighbourhood, civil society or political communities. Choosing not to be where they have decided to congregate means not being able to do my job and not making my voice heard where many decisions affecting me are taken.
Yes. AI is becoming the content launderer. I mean what's the difference? You could ask an AI to make not star wars. And what's the difference between that and all the not star wars movies made in the 80s? It's that it was automated this time around?
I think this points out that AIs clearly do not work like human brains. Human brains do not need all of the content of humanity to produce a replica of art station mediocre.
It's not like there's many alternatives, network effects are very powerful and even with Musk running the company into the ground, there's not many people really quitting which tells a lot on how hard that effect can be.
They have announced a plan to compensate creators based on ads shown and also have implemented a subscribers feature (people paying users for special access to some tweets)
The actual problem seems to be that a large number entities now want a full copy of the entire site.
But why not just... provide it? Charge however much for a box of hard drives containing every publicly-available tweet, mailed to the address of buyer's choosing. Then the startups get their stupid tweets and you don't have any load problems on your servers.
What do you even charge for that? We might never make a repository of human made content with no Ai postings in it ever again. Seems like selling the golden goose to me
Substantially higher loads than Twitter gets today were not "melting the servers" until Musk summarily fired most of the engineers, stopped paying data center (etc.) bills, and then started demanding miscellaneous code changes on tight deadlines with few if any people left who understood the consequences or how to debug resulting problems.
In other words, the root problem is incompetent management, not any technical issue.
Don't worry though, the legal system is still coming for Musk, and he will be forced to cough up the additional billions (?) he has unlawfully cheated out of a wide assortment of counterparties in violation of his various contracts. And as employee attrition continues, whatever technical problems Twitter has today will only get worse, with or without "scraping".
Scraping has a different load pattern than ordinary use because of caching. Frequently accessed data gets served out of caches and CDNs. Infrequently accessed data results in cache misses that generate (expensive) database queries. Most data is infrequently accessed but scraping accesses everything, so it's disproportionately resource intensive. Then the infrequently accessed data displaces frequently accessed data in the cache, making it even worse.
Caches are only so large. Expanding them doesn't buy you much, and increases costs greatly.
The key benefit to a cache is that a small set of content accounts for a large set of traffic. This can be staggeringly effective with even a very limited amount of caching.
Your options are:
1. Maintain the same cache size. This means your origin servers get far more requests, and that you perform far more cache evictions. Both run "hotter" and are less efficient.
2. Increase the cache size. Problem here is that you're moving a lot of low-yield data to the cache. On average it's ... only requested once, so you're paying for far more storage, you're not reducing traffic by much (everything still has to be served from origin), and your costs just went up a lot.
3. Throttle traffic. The sensible place to do this IMO would be for traffic from the caching layer to the origin servers, and preferably for requesting clients which are making an abnormally large set of non-cached object requests. Serve the legitimate traffic reasonably quickly, but trickle out cold results to high-demand clients slowly. I don't know to what extent caching systems already incorporate this, though I suspect at least some of this is implemented.
4. Provide an alternate archival interface. This is its own separately maintained and networked store, might have regulated or metered access (perhaps through an API), might also serve out specific content on a schedule (e.g., X blocks or Y timespan of data are available at specific times, perhaps over multipath protocols), to help manage caching. Alternatively, partner with a specific datacentre provider to serve the data within given facilities, reducing backbone-transit costs and limitations.
5. Drop-ship data on request. The "stationwagon full of data tapes" solution.
6. Provide access to representative samples of data. LLM AI apparently likes to eat everything it can get its hands on, but for many purposes, selectively-sampled data may be sufficient for statistical analysis, trendspotting, and even much security analysis. Random sampling is, through another lens, an unbiased method for discarding data to avoid information overload.
Twitter feels more stable today, with less spam, than one year ago. There's of course parts that have been deliberately shut down, but that's not an argument about the core product.
Pandemic lock downs are 99% over. People are getting back outside and returning to office. These effects have little to do with Twitter's specific actions.
I see more spam these days, particularly coming from accounts that paid for the blue check mark. IIRC, Musk said that paid verification would make things better since scammers wouldn't dare pay for it (I would find where he said this but I hit the 600 tweet limit), but given how lax their verification standards are, it seems to be a boon to scammers, much the same way that Let's Encrypt let anyone get a free TLS cert at the cost of destroying the perceived legitimacy that came with having HTTPS in front of your domain.
(And IMO, that perceived legitimacy was unfounded for both HTTPS and the blue check before both were easy to get, it's just that the bar had to drop to the floor for most people to realize how little it meant.)
The "massive layoffs" was just twitter returning to the same staffing level they had in 2019, after they massively overhired in 2020-2021. This information is public, but this hasn't stopped people from building a fable around doomsday prophecies.
I mean, it’s clear the Musk overcorrected. The fact that managers were asked to name their best employees, only to then be fired and replaced by them, or that musk purposefully avoided legal obligations to pay out severance/health insurance payments (I forget the exact name)/other severance, and that the site has had multiple technical issues that make it feel like there’s no review/QA process all show that he doesn’t know what he’s doing.
He got laughed out of a Twitter call thing with lead engineers in the industry for saying he wanted to “rewrite the entire stack” and not having a definition for what he meant.
Doomed or not, Musk is terrible at just about everything he does and Twitter is no exception
I think that’s always been known, but the tacit agreement between users and Twitter has always been “I’ll post my content and anyone can see it, if they want to engage they make an account”. From a business perspective this feels like a big negative to me for Twitter. I’ve followed several links the last few days and been prompted to login, and nothing about those links felt valuable enough to do so.
It's about $1 per thousand tweets and access to 0.3% of the total volume. I think the subscription is 50M "new" tweets each month? There are other providers who continually scrape Twitter and sell their back catalogue.
Researchers are complaining that it's far too high for academic grants. Probably true, but that's no different from other obscenely priced subscriptions like access to satellite imagery (can easily be $1k for a single image which you have no right to distribute). I'm less convinced that it's impossible for them to do research with 50 million tweets a month, or with what data there is available. Most researchers can't afford any of the AI SAAS company subscriptions anyway. Data labelling platforms - without the workers - can cost 10-20k a year. I spoke to one company that wouldn't get out of bed for a contract less than 100k. Most offer a free tier a la Matlab in the hope that students will spin out companies and then sign up. I don't have an opinion on what archival tweets should cost, but I do think it's an opportunity to explore more efficient analyses.
Honestly I think that's why reddit is closing itself up too. Everyone sitting on a website like this might be sitting on a Ai training goldmine that can never be replicated.
Too little too late. Anything pre-ChatGPT is already scrapped, packaged and mirrored around the Internet; anything post ChatGPT launch is increasingly mixed up with LLM-generated output. And it's not that the most recent data has any extra value. You don't need most recent knowledge to train LLMs. They're not good for reproducing facts anyway. Training up their "cognitive abilities" doesn't need fresh data, it needs just human-generated data.
Precisely, which brings us back around to the question: why are social media companies really doing this?
I think "AI is takin' ooor contents!" is a convenient excuse to tighten the screws further. Having a Boogeyman in the form of technology that's already under worried discussion by press and politicians is a great way to convince users how super-super-serious the problem must be, and to blow a dog whistle at other companies to indicate they should so the same.
It's no coincidence that the first two companies to do this so actively and recently are both overvalued, not profitable, and don't actually directly produce any of the content on their platforms.
I've seen that work with self-driving cars. Simulating driving data is actually better since you can introduce black swan events that might not happen often in real world.
Are you really sure it's legal? In theory it's not different from providing the same information from API or website... but do people working in law think so?
Twitter purchased Gnip years ago, and it's a reseller of social media data. Companies that want all the public tweets, nicely formatted and with proper licensing, can just buy the data from Twitter directly.
I'm assuming their terms give them permission to redistribute everybody's tweets, since that's kind of the whole site. I don't know why they'd restrict themselves to doing it over the internet and not the mail, but do you have any reason to think that to be the case?
So, I'd just made that suggestion myself a few moments ago.
That said, there are concerns with data aggregation, as patterns and trends become visible which aren't clear in small-sample or live-stream (that is, available in near-time to its creation) data. And the creators of corpora such as Twitter, Facebook YouTube, TikTok, etc., might well have reason to be concerned.
This isn't idle or uninformed. I've done data analysis in the past on what were for the time considered to be large datasets. I've been analyzing HN front-page activity for the past month or so, which is interesting. I've found it somewhat concerning when looking at individual user data, though, here being the submitter of front-page items. It's possible to look at patterns over time (who does and does not make submissions on specific days of the week?) or across sites (what accounts heavily contribute to specific website submissions?). In the latter case, I'd been told by someone (in the context of discussing my project) of an alt identity they have on HN, and could see that the alternate was also strongly represented among submitters of a specific site.
Yes, the information is public. Yes, anyone with a couple of days to burn downloading the front-page archive could do similar analysis. And yes, there's far more intrusive data analytics being done as we speak at vastly greater scale, precision, and insights. That doesn't make me any more comfortable taking a deep dive into that space.
It's one thing to be in public amongst throngs or a crowd, with incidental encounters leaving little trace. It's another to be followed, tracked, and recorded in minute detail, and more, for that to occur for large populations. Not a hypothetical, mind, but present-day reality.
The fact that incidental conversations and sharings of experiences are now centralised, recorded, analyzed, identified, and shared amongst myriad groups with a wide range of interests is a growing concern. The notion of "publishing" used to involve a very deliberate process of crafting and memoising a message, then distributing it through specific channels. Today, we publish our lives through incidental data smog, utterly without our awareness or involvement for the most part. And often in jurisdictions and societies with few or no protections, or regard for human and civil rights, let alone a strong personal privacy tradition.
As I've said many times in many variants of this discussion, scale matters, and present scale is utterly unprecedented.
This is a legitimate concern, but whether the people doing the analysis get the data via scraping vs. a box of hard drives is pretty irrelevant to it. To actually solve it you would need the data to not be public.
One of the things you could do is reduce the granularity. So instead of showing that someone posted at 1:23:45 PM on Saturday, July 1, 2023, you show that they posted the week of June 25, 2023. Then you're not going to be doing much time of day or day of week analysis because you don't have that anymore.
Yes, once the data are out there ... it's difficult to do much.
Though I've thought for quite some time that making the trade and transaction of such data illegal might help a lot.
Otherwise ... what I see many people falling into the trap of is thinking of their discussions amongst friends online as equivalent, say, to a discussion in a public space such as a park or cafe --- possibly overheard by bystanders, but not broadcast to the world.
In fact there is both a recording and distribution modality attached to online discussions that's utterly different to such spoken conversations, and those also give rise to the capability to aggregate and correlate information from many sources.
Socially, legally, psychologically, legislatively, and even technically, we're ill-equipped to deal with this.
Fuzzing and randomising data can help, but has been shown to be stubbornly prone to de-fuzzing and de-randomising, especially where it can be correlated to other signals, either unfuzzed or differently-fuzzed.
I despise Musk as much as anyone else and charging for API access has hurt a lot of valuable use cases like improving accessibility but … how about not massive scraping a site that doesn’t want you to?
Scraping isn’t illegal, and to be honest, I’m not even sure it’s unethical. I’m assuming you think it so — if so, why? I’m not disagreeing, but haven’t given it much thought.
Having been to twitter mostly through the most recent prominent war, man the signal to noise ratio is really low even when being careful about who to follow and who to block. There is so much disinformation, bad takes, uninformed opinions presented as facts, pure evil, etc.
So I guess it could be used for training very specific things or cataloging the underbelly of humanity but for general human knowledge it’s a frigging cesspool.
OK, not gonna argue with that. There is, I guess, a perception that it matters because policy-makers, and the wonks and hacks that influence them are hooked. The value for me (and ergo the public, some classic NGO thinking there for you) lies in understanding those dynamics.
I do not use the Twitters myself, and actively discourage others from doing so. Sends people bonkers.
I mean, we have found election manipulations like large-scale inauthentic activity of out-of-staters explicitly targeting African Americans, and projects here even to the extent of the perpetrators getting indicted. Other projects were tracking vaccine side-effect self-reports faster than the CDC and other disaster intelligence.
We were actually gearing up to switch to paid accounts as we found use cases that could subsidize these efforts... And then the starting price for reasonably small volumes shot up to like $500k/yr.
So, are we saying it's unethical for Google and other search engines who make money off of ad revenue to scrape sites like Twitter? Or are they paying a large sum to Twitter to do this?
When there is a value exchange between the two entities that are relatively similar then I think it is ethical. People trade Google making money on ads for their site being found when people search. It is also possible to opt-out.
But it's it ethical for the site owner to block access to random people and companies in the internet to _my_ data? I posted that tweet with the expectation that it's gonna be publicly available. Now the owner of the site is breaking that expectation. I would say that this part is also unethical.
Especially since they're not moderating things or anything.
Agreed. However, it's probably covered by their terms of service.
Same thing with the recent reddit kerfuffle. I'd have much preferred a Usenet 2.0 instead of centralizing global communications in the hands of a handful of private companies with associated user-hostile incentive structures.
Being indexed by google is optional. Twitter could stop it a any time if they thought it was a bad deal for them. That not comparable to a startup company trying to scrape the entire site to train their AI and using sophisticated techniques to bypass protections Twitter has put in place
Except with modern software, some wannabe genius programmer will think they can get a bunch of money or cred or whatever by infantilizing the process down to something your grandma could use. Then, suddenly, everyone is scraping. The net effect is largely the same -- server operators see an overwhelming proportion of requests from bots. Still ethical?
Yes, it is ethical. In many countries it is legal for humans to walk around the public square and overhear all conversations.
It is NOT legal to install cameras that record everyone's conversations, much less sell the laundered results.
Pre-2023 people went on Twitter with the expectation that their output would be read by humans.
A traditional search engine is different: It redirects to the original. A bastardized search engine that shows snippets is more questionable, but still miles away from the AI steal.
Many countries have freedom of panorama, which means it is legal to video record the public square. I'm not aware if anywhere has specific laws on mounting the camera on a robot.
If the background of the issue is as Musk described, then it certainly is not allowed by twitter’s robots.txt, which allows a maximum of one request per second.
I do a lot of data scraping, so I’m sympathetic to the people who want to do it, but violating the robots.txt (or other published policies) is absolutely unethical, regardless of the license of the content the service is hosting. Another way of describing an unauthorised usecase taking a service offline is a denial of service attack, which (again, if Musk’s description of the problem is accurate) seems to be the issue Twitter was facing, with a choice between restricting services or scaling forever to meet the scrapers requirements.
Personally I would have probably tried to start with a captcha, but all this dogpiling just looks like low effort Musk hate. The prevailing sentiment on HN has become so passionately anti-Musk that it’s hard to view any criticism of him or Twitter here with any credibility.
This isn't going to make them stop either. Musk is about to see a spike in account creations using the method of lowest resistance. I expect "sign in with apple" will disappear as an option soon, given its requirement of supporting "hide my email" that makes it trivial to create multiple twitter profiles from one apple ID.
And yet people do. Kind of predicting what various people react including scammers, bots, scrapper and what not is, like, job of a management in a company like this.
He holds views that were the progressive norm 15 years ago, which are now considered bigoted, this is considered unacceptable today. There's a lot I don't agree with him on, like Ukraine, but "despise" is a word I reserve for the likes of Putin.
I don’t think Putin is the epitome of evil that the west portray him to be either. War is hell and he surely started the larger scale war, but just remember that you’ve probably been introduced to less than 1% of his side of things as a western citizen. The western world has gone to war many, many times in history for lesser reasons.
What do you know about Putin’s motives? What propaganda do you think you’re under?
You’re probably smart enough to understand that out of spite and regret of your country’s history with the Russians your countrymen have more motivation than many others to judge the Russian efforts without any further investigation into the matter.
The same applies for myself, since I’m Finnish. It’s almost sad to see how people abandon all reason and critical thinking skills because of some ingrained belief that “Russia bad”. All of my knowledge of the human nature leads me to believe that they’re no more bad than the next people, and that they probably have some motives to go to a taxing war that we don’t really understand here in the west - seeing as the first casualty in war is the truth.
>Yeah he started the one of the deadliest wars in the 21 century, threatens to destroy the entire planet with nuclear weapons, but he is not that evil because there were other wars started by the west
I’ll rephrase your argument for you: “Why don’t you listen to the rapist’s opinion? The victim is surely not blameless. Besides, your cousin is a shoplifter”.
Would his side of the story matter to you? I don’t think it’s a particularly nuanced point to you since you’ve already made up your mind, however ignorant it might be.
Putin already gave his side of the story. He declared Ukraine an invalid country, said there were nazis there and then went into full out war to destroy the country while committing countless atrocities.
I don’t think it’s a particularly nuanced point to you
What point and why do you keep saying 'nuance' over and over while giving zero actual information? What are you trying to say and what evidence is there?
Let's think about this super hard. What is the justification for an unprovoked genocidal war? Why are you defending putin?
however ignorant it might be.
Show me where you get your information, lets see the source of this nonsense.
1. As already mentioned, it's hardly a nuanced point.
2. If you actually want to hear my opinion, then the realm of geopolitics + good old-fashioned hate of the US government does a number on people's logic, so we get what I can only charitably describe as a parade of non-sequiturs, whataboutisms and other fallacies. And so it can be useful to frame it in the simpler terms, for example you could hardly find anyone even on this site who would condone the forced takeover of parts of people's homes. Literally the same is happening on a scale of the countries.
API rate limits are more easily enforceable. If they keep scraping there are methods to detect and thwart behaviour. I don't think twitter has the appropriate talent and work environment to allow proper solutions to be implemented. It's all knee jerk reaction to whatever Elon decides.
It's more easily enforced, except when you don't give them enough they just go back to scraping. Or create a million fake developer accounts and pool the free quota if that's possible. These are not hypotheticals, loads of companies have done both against all kinds of APIs over the years, Twitter included.
But they were too stingy with the tiers and too greedy with their prices. Even for minor use cases where you need to make, say, 100 API calls a day, you’ll need to pay $100/month.
I'm not going to pay $100 just to fetch 3000 records for a hobby project. I'll either skip the project, or I'll just abuse my scraping tool.
If they'd made some more reasonable pricing tiers, I would have been happy to pay.
Fetching something as simple as the total follower count from an API shouldn't be more (exorbitantly) more expensive than fetching data from, say, GPT-4. No reasonable person can make an argument for $10c/call pricing.
Did you actually read that comment? I think the point is very clear -- given a reasonable price, people may would want to use the API instead of scaping the data themselves. If you instead ask for exorbitant amount of money, it only forces people to scrape, because there is no business model that would make it possible to pay.
Sorry I don’t buy it. Hundreds of millions of people use Twitter, and we are to understand that there are an enough people scraping to the extent that they had to suddenly take drastic action by shuttering unauthenticated access? Any dev would have told him that those supposedly scraping could simply setup Selenium or some other headless browser to login before scraping.
This smells of another failed Musk experiment at twiddling with the knobs to increase engagement, to me.
A bot scraping content will tend to go deep into the archives and hit all content systematically. Caching isn't as effective if you hit everything whereas real users will tend to hit the same content over and over again.
You don't generally need to accept licenses in order to scrape something, only if you want to distribute it.
The legal ambiguity comes from the question of whether LLM outputs are a derivative work of the training data. I expect that they aren't, but anything can happen.
> Hundreds of millions of people use Twitter, and we are to understand that there are an enough people scraping to the extent that they had to suddenly take drastic action by shuttering unauthenticated access
Suppose 1 million people are accessing Twitter at any given time. An actual person might only be making 1 request / second. That's 1 million requests / second.
Suppose there are 100 AI companies scraping Twitter. A bot like this can make thousands to tens of thousands of requests per second. That's an additional million requests / second.
There are probably more than 100 "AI" companies now, trying to train their own bespoke LLMs. They're popping up like weeds so I can totally see Twitter's load doubling or tripling recently. So sorry, I just don't get the skepticism. Sure it could be a cover for something else, but his actual stated reason seems totally possible.
It’s not a little “use selenium” switch you can click, but it absolutely is an option (and there are others) if the barrier is simply to have an authenticated account and be logged in.
If these data scraping operations are as sophisticated and determined as he claims this measure is insufficient and actually it really hurts Twitter far more than it helps. Case in point: we stopped sharing Twitter links because when you click them in most iOS apps it opens up an unauthenticated web view and presents you with a login screen. So we just collectively decided “ah ok no sharing Twitter” and moved on.
I’m sure there are companies scraping Twitter. I just don’t buy that it’s as big of an issue as he claims it is, and that preventing people from viewing tweets without logging in is a way to mitigate against that (I’d first look at banning problematic IP addresses first, personally).
To me it’s either:
1) a very poor and very temporary mitigation against scraping, that could be bypassed with a bit of effort
2) an experiment in optimising metrics - Musk sees lots of unauthenticated users consuming Twitter, tries to steer them into signing up
3) it’s all just a big mistake
Option #2 makes the most sense to me, but frankly none of them are good
A decade ago I worked on building AI systems that made (legitimate, paid) use of the Twitter “firehose”. At that time more than 99% of the data was garbage. It’s worse now. The value then was largely in two areas: historical trends (something like Google trends), and breaking news; and only the latter was really that interesting. I doubt it’s a high value data source scraped in bulk; it could have value in a much more targeted approach. Seems unlikely to require the addition of “large numbers of servers … on an emergency basis”.
Seems to entertain many so has value in that sense I guess. Plus perhaps post vs replies make some sort of challenge & response pair that can be leveraged?
This makes no logical sense. Why would the scraping not restart after its unlocked? More realistically, he got a lot of backlash from users and website owners where embedded tweets suddenly stopped showing up.
I used to work for a very large financial institution. Scraping from finance apps was a material source of load even with substantial countermeasures in place. I can’t imagine what it does to sites like Twitter and Reddit (and HN).
HN volume is absolutely tiny (the ids are sequential so you can easily check how many items there are in a given day) and there’s an API. It’s no comparison.
He's been somewhat critical of OpenAI. Specifically the part about it pivoting to a for-profit business.
> I’m still confused as to how a non-profit to which I donated ~$100M somehow became a $30B market cap for-profit. If this is legal, why doesn’t everyone do it?
I assume you are joking. In case you aren't, start with the subject of this very thread ($100M claimed Vs $10M reality). Then work backwards through every claim he ever made about anything. Here's a collection of his top hits https://www.elonmusk.today/
He tried to pressure them in 2020 to make him a CEO. They refused, so he pulled promised funding when they were on the brink of bankruptcy. They made a deal with Microsoft instead.
Then in 2022, they blew up and Elon's been spitting venom at them ever since as he missed his chance.
He had committed to providing funding to them and was on the board. Being on the board is indeed the only form of control in a non-profit.
He tried to pressure them to make him a CEO, they refused, so he said "no money then, go bankrupt" and quit the board. They made a deal with Microsoft and survived.
Disables API, gets scraped, needs more servers, disables access without logins, gets millions of fake accounts, has to deal with the fake accounts, in the process deletes tons of real accounts, users pissed, scraping continues, server bills keep rising...
I think it will be sort of interesting to see what AI scraping does to the open internet.
I think that we are already putting too much content into Social Media platforms (HN included). Stuff that we sort of ought to self host because then we would actually own it. But will you even want to run your own sites publicly if they are getting scraped? I guess it’s it really a new issue as such, but I imagine it’ll only get worse as the LLM craze continues to rise.
You haven't been able to look at anything but the /explore endpoint for weeks without an account, and the "content" on there has been total garbage.
I was relieved when they started asking for an account this week because now I'll finally be able to break my habit of navigating to Twitter to "see what's happening" only to find a bunch of sports memes, pop music drama, or right-wing trolls pretending like Hunter Biden is the most nefarious person on the planet.
Imo, Elon is lying and he locked everything down for PR so he would make a headline and frame it like his site's content is _so valuable_ that he just had to take drastic measures to stop AI from training on it.
He's not wrong on this occasion, there are multiple companies out there, some even with a multi-billion dollar valuation that "farm" tweets for many reasons.
Planet Earth Inhabitants in 2023: 8 Billion -> Social Media Users -> 4.8 Billion -> Twitter Users -> 368 million active users who engage at least once a month.
If those AI Models are being trained on a reduced set of 3% of human beings, they will lose a lot.
Less likely the reason is technical / cost of service (which is very cheap) and more likely he is trying to exercise leverage in pursuit of monetizing engagement (which had already happened [1] ). It’s not that he broke the website’s tech but rather he broke the website’s business.
The above comment doesn't deserve to be downvoted. If Musk wants people to believe his statements, he should have refrained from being a serial liar. Now his reputation is in the trash, and he has only himself to blame.
In fairness, the first part of my comment is a personal attack that could have been left out. But the second part is what you're agreeing with, that he doesn't have credibility because of making stuff up a bunch recently. And I think that's right.
I wonder if it's people seeking to move away from Twitter and working around crippled APIs, or if it's ClosedAI in which Musk himself invested before...
I appreciate that attitude and value it myself, but I like to point out that it is not without risk.
If the world around HN (including its community) changes, stasis can damage or kill it as well.
Specifically regarding the issue of the original posting:
- HN is already an important data source for large language model training. [1]
- To the best of my knowledge there is no freely downloadable and current data dump of HN. [2]
- The HN-API does not offer all the data that scraping can get. For example, if a post had ever hit the front page or the highest front page position reached, is an interesting data point that is missing.
- The Algolia-HN-API has the same limitations.
In my opinion this will lead to increased usage of the API and increased scraping which all costs money. HN might be forced to find a solution for this.
[1] For example, the RefinedWeb paper lists HN as one of only 12 websites that were excluded. From what I understand, it was excluded because it went into the final dataset unvetted. RefinedWeb was used for the Falcon model.
[2] The closest thing is probably the Google BigQuery "bigquery-public-data.hacker_news" dataset.
It claims to be updated daily, but really is from late September 2022. Also I could not find the download link which other data sets offered on BigQuery have. Does anyone know if I can download the complete thing anyhow?
I don't expect HN give a fuck about the scraping. It's pure HTML, no images, probably cached all to hell for users who aren't logged in anyway.
The one thing I see as a future issue is that people are starting to post comments that clearly look like they were manufactured by ChatGPT and friends. Or that could just be the way some people talk and I've spent too long with ChatGPT now and start to smell it everywhere.
HN does have performance / capacity issues, and you'll find that if you're crawling the site rapidly, you'll quickly have your IP banned.
I've had that happen even under manual browsing (when logged out). My front-page analytics project hit that limit quickly (within about 30 requests, probably less). Adding in a reasonable delay got around that.
Keep in mind that a lot of Web infrastructure tends over time to operate just at the edge of stability, as capacity costs money.
This attitude that: if it ain't broke, don't destroy it, is something I'm finding myself valuing increasingly. I use Stylish to make HN look a bit more readable and prettier, and beyond that, it functions exactly how I want it to and I'm glad to see that the institutional momentum here is a core value.
That's actually a nice way of putting it! Better than the "fix" version, because this is clear on the consequences.
I feel like it might be applied to everything from OS UI design (Windows 11), web platform redesigns (Google's icons) to whatever is going on with social media (the silly enshittification term describes this) and many other things.
Let's say that you are the proud owner of a goose that lays golden eggs. "fixing" would be switching it to a different feed that might make it more productive, or it might make it sick. But this year the trend is to give it a few good kicks to see if that helps.
I’ve been here for 6 years and the format is still a breath of fresh air when I come back from things like Twitter or Reddit.
It’s not that I’m opposed to change really. I love good ideas, and being surprised by new and unfamiliar things is usually a joy. Communication via text is hard to improve upon though, and I’m not convinced any major social media platforms have found ways to improve this in any meaningful ways.
I want to read interesting things and discuss them with interesting people. This is hard on most platforms. HN makes it easier than everything else I use.
You did say, recently, that you don't like the idea of paid third-party apps using the HN API.[0]
I thought that was an odd change for HN. After all, the majority of the value still accrues to the HN owners. In fact, user's that are prepared to pay for an app to access a free website largely comprised of adverts, are typically more valuable than the rest. Those users have money to burn and skin in the game!
That's a fine point. I just get uncomfortable with it because the currency of HN should be curiosity, not money, so energetically it doesn't feel like a good fit.
Elon says he used it as a way to stop AI data scraping because the servers were suddenly hit by a large load.... (As a weird form of DDOS shielding in other words)
HN could be hit with such a large load too, since we have pretty good and lengthy discussion here, good for AI data training.
Would you believe it a valid tool to keep the community happy?
Since I doubt we would be happy if we can't access the site because some AI decided this was the time to scrape, either.
I agree that it could become a problem but I'd rather wait until the problem shows itself clearly, rather than (potentially) over-reacting in advance. Sometimes the medicine turns out to be worse than the disease; plus it's a better fit for being lazy.
I'd love to see the source control change log for HN. I can't even remember a single visible change in all the years I've been a user. I think there have been a few under the surface though.
I wish all the other sites on the Internet would wake up every morning, look at their TODO list and say "Nah, not today."
It's ambiguous what GP refers to as "next", but if it's the Eternal September part, I believe HN unfortunately already suffers a lot from it. In my subjective opinion, comment quality took a nosedive in the past 2-3 months or so. That said, I have no idea how to fix it, if it needs fixing at all.
I'm not saying you're wrong and anyway it is hard, if not impossible, to evaluate objectively—but I can tell you two things for sure. One is that people have been saying more or less exactly this about HN for at least 15 years; the other is that HN is subject to a lot of random fluctuations, and random swings tend to get interpreted by humans as long-term trends—not because they are, but because that is what humans do.
In addition to my sibling comment: HN also steps in to quash developing negative patterns in all sorts of ways. There's a long list of banned sites, there is the flamewar detector (though I've ... questions ... about that), dupes detection (or flagging), there are weightings and penalties given to various sites. I believe also some keyword and other patterns are looked for as well, "Reddit" being among ones dang's recently discussed.
So yes, occasionally some new pattern or trend will emerge, but HN adapts to those fairly quickly.
Paralleling what dang's said here, I've been looking at 17 years of HN front page activity over the month or so, and am starting to tackle the question of topic drift and/or focus over that period.
My current tack involves looking at sites (as reported in parentheses at the end of each HN front-page post title) and classifying those. With slightly more than 30% of sites categorised, I can classify about 65% of all HN posts.
For the full dataset (17 years), that's roughly:
1 63913 35.73% UNCLASSIFIED
2 22589 12.63% blog
3 15112 8.45% general news
4 13823 7.73% tech news
5 12851 7.18% programming
6 8622 4.82% corporate comm.
7 8459 4.73% academic / science
8 7294 4.08% n/a
9 5324 2.98% business news
10 3803 2.13% general interest
11 2151 1.20% social media
12 2074 1.16% software
13 1613 0.90% technology
14 1463 0.82% video
15 1144 0.64% general info (wiki)
16 1009 0.56% government
17 724 0.40% misc documents
18 720 0.40% law
19 702 0.39% tech discussion
20 620 0.35% science news
Tons of caveats: this depends heavily on how I classify individual sites, a given site's stories might well be technical, social, or political, etc., etc.
The breakdown-by-year analysis is in development, but if anything programming-specific content as increased in prevalence. Political discussion seems not to have (though it rose significantly ~2014). Cryptocurrency and blockchain-specific sites also peaked about that time (I suspect much of that discussion is now mainstream). General news has always been a huge portion of HN discussion, as have individual (and corporate) blogs.
Note again that this isn't about discussion and comments, or even the titles or article contents (I'm thinking of looking at those, it's ... a challenge for me).
But across nearly 200,000 front-page stories, on which nearly half of all HN discussion occurs (based on another API-based study looking at comprehensive posts), the overall trending seems at first blush to be pretty consistent and if anything improving over time.
(As with all preliminary results, I'm hoping I won't have to eat my words here. Though I'm reasonably confident in most of this.)
From the classifications above, the places you might find some that "suffering" would be in general news, genral interest, and social media categories. All but the first of those are single-digit percentages, and a lot of that general-news content is about technology, business, finance, and science, all of which would crowd out the sort of social and political issues which seem to generate strong feelings.
The "UNCLASSIFIED" sites are a wide mix, though most are probably a mix of blogs, corporate / organisational communications, and the like. The mean posts per site is 1.739951, so gains from additional site-categorisation are pretty slim. I have captured a lot of obvious patterns via regexes and string matches, so academic/science and major (or even minor) blogging and social media sites aren't a large fraction.
More on "UNCLASSIFIED": there are 36,520 of those sites.
It's not practical to list all of them. But we can randomly sample. And large-sample statistics start to apply at about n=30, so let's just grab 30 of those sites at random using `sort -R | head -30`:
That's a few foundations, a few blogs, a corporate site (enterprise.google.com), and something about tea, all with a small number of posts (1--7).
I'm looking at some slightly larger samples (60--100) here on my own system, and can actually make some comparisons across samples (to see how much variance there is) which can give some more information on tuning what I would expect to find under the "UNCLASSIFIED" sites.
Fair enough! Personally one thing I would like is some sort of inbox functionality to notify you if someone replies to your comment, but can definitely live without it!
One welcome addition would be support for embedded images - sometimes you need to share some screenshots. For example right now, I am seeing rate limiting messsages from Twitter, from the normal account.
I think of features like this on a regular basis that this site needs. Then I catch myself. It's feature-creep like that which has killed practically everything else.
They have so far and have reason to continue to, not just because of how they feel about HN but because the economics of curiosity are a good fit for YC's business. That's the miracle (I would even say) about HN - it occupies a sweet spot where it can be funded to just be good*, and the economics work because it's in the interests of the business.
The choice is not between no change and drastic change, but selecting a rate of change that is appropriate. Things which do not change, die, as the only thing that is constant is change. Change or be changed.
I visit a few sites that never changed (or at least changed things only few were even aware of) and they live long enough to lose count of hordes of change-praisers appear and die.
I believe this eternal loop of change is a trap that impatient people force themselves in. Instead of accustoming and learning the current state, they rush into another one with a change that has unclear implications. As a result, they never get where they are and lose any track of where they were or where they’re heading at. Their only comfort can be found in a constant change.
These few sites are like home to me. One of them I visit with years-long pauses and every time I return it’s the same user experience. That’s invaluable.
Sharks haven't changed in about 450 million years. There are designs that just work and don't need to change unless the environment changes drastically.
For me the main barrier is that I want to have portable/roaming control over my IDENTITY, even if the content hosting is (for now) entirely through a system administered by someone else. If I control the identity, I can at least keep local copies and rehost/repost content later.
Instead, it feels like the current Fediverse demands that I make a blind choice to entrust not merely a copy of my content but also my whole future identity to whatever of these current instances looks the most stable/trustworthy at first glance, hoping my choice will be good for 1-5-10-15 years. It's stressful, and then I look into self-hosting, and then I put the whole thing off for another week...
AFAICT I would need to set up a whole federated node of my own in order to get that level of identity-control. Serious question: Is there any technical limitation preventing the admin of an instance from just seizing an particular account and permanently impersonating the original owner?
In contrast, I was hoping/expecting some kind of identity backed by a private asymmetric key. Even if signing every single message would be impractical, one could at least use it to prove "The person bob@banana.instance has the same private key that was used to initialize bob@apple.instance."
This is basically the entire point of the Authenticated Transfer Protocol (AT Protocol), which powers Bluesky. I think it does a ton of stuff right, including portable identity backed by solid cryptography (no blockchain or "crypto"!) and has a lot of promise. It's still in development, but I am hopeful that it will live up to its promise.
Yes, at the end of the day a malicious client is always a risk with this sort of thing. But the AT Proto does have some mitigation in place—users have a signing key which their PDS needs to act on their behalf (sign posts, etc) and a separate recovery key which users can hold fully self-sovereign and use to transfer their identity in case they detect malicious behavior. It's not foolproof of course, nothing is, but it is thoughtfully designed.
But yes, the protocol does have a fair bit of trust of your PDS built in. But that's inevitable for decent UX—imo the crypto craze proved that basically no one wants to (or can) hold their own keys day-to-day. If you want to have a cryptographic protocol that the average person can use, some amount of trust is necessary. The AT Protocol artfully threads the needle and finds a good compromise that is a (large) improvement over the status quo, in my opinion.
In theory, kinda, but you can bring-your-own client, and "the" web client is decoupled from the back-end instance.
"bsky.app" works as a web client for the official "bsky.social" instance, but it also works with the instance I self-host (or any other spec-compliant instance). Likewise, 3rd party clients work with the official instance, and also with 3rd party instances.
However, no key-stealing could possibly happen right now in any case because... the PDS ("instance") holds your signing key - the client never even sees it. Having the server hold your signing keys is very user-friendly, but of course not ideal for security and identity self-sovereignty. In general, the security model involves trusting your PDS (just as you trust your mastodon instance admin, or twitter dot com - the improvements are centered around making it easier to jump ship if you change your mind).
Client-signed posting is something that's not even possible right now, but I believe it's somewhere on the roadmap. If it doesn't happen some time soon I'll be implementing it myself. (I'm writing my own PDS software)
That's never going to work for the average person, sadly. And it misses a lot of social features that a lot of people (myself included) want from social media. Simply put, the UX is way too far off what people want and need.
It will, ISPs just need to start providing the basic hosting infrastructure on their routers again, like they used to. Thankfully we're also at a time where IPv6 is mature enough so that this is greatly simplified !
Wordpress doesn't have ActivityPub built in, it's a plugin in beta currently. Without AP, there is no client that can pull in website feeds and provide discoverability between WordPress sites, Mastodon posts, etc.
Back in the old days, activitypub was my Rss feed reader. Discoverability was driven by good old fashioned cross linking, comment discussions, and skimmable feeds from aggregators like the one we're on.
People love to reinvent the wheel and claim it's a whole new thing. No ideas on the web have really been innovative since the bubble popped. The innovation has all been on delivery and execution (not wanting to discount any of that).
Sure it is? WordPress updates itself and all plugins automatically. I've had Wordpress sites running for over a decade with zero security concerns ever popping up.
> For me the main barrier is that I want to have portable/roaming control over my IDENTITY, even if the content hosting is (for now) entirely through a system administered by someone else. If I control the identity, I can at least keep local copies and rehost/repost content later.
This is why I want domains as identities to succeed. I want to own my handle on every platform, but I don’t want to self host.
Do you know of any existing projects in this space?
I was toying with an idea/protocol where:
1. You add a TXT/CNAME that points to a trusted "authentication provider".
2. When you try and login to a website that supports the protocol, it checks the DNS record and redirects you to your provider.
3. You then "prove" that you own the domain to the provider - how this is done would be specific to each provider, but one possible method could be by providing a signed message that can be verified vs. a public key stored in a DNS record.
4. The provider redirects you back to the original website with a token.
5. Finally the original website consumes this token by sending it in a request to the provider. The response contains the domain as confirmation of the user's identity.
This approach removes the need for self-hosting as users can point and setup their names with third party providers.
Users can also trivially switch to a different/self-hosted provider by changing the CNAME.
Communities could also allow direct registration by hosting their own provider instance and pointing a wildcard subdomain at it: (i.e. *.users.ycombinator.com).
Users could then sign up to said provider using traditional email/password and claim a single subdomain: (i.e. tlonny.users.ycombinator.com)
Sounds they want self custody of their keys. This isn't what the general public want.
Decoupling identity from social is a good idea but you can't just migrate the key storage to a single custodian entity. There'd need to be a multiple custodians to ensure the same power imbalances didn't reappear in a different form (e.g. Google owning everyone's logins).
Exactly. There is no magic trustable non-local/distributed system that replaces 'self-hosted' for this purpose.
All that is needed is a to create your local identity (e.g. like storing fingerprint biometrics on your laptop) and a clever way to sync between physical devices (e.g. through bluetooth).
We're in this weird situation where people don't want to be responsible for managing their own data/id, but can't trust others to do so for them.
I raised issues on mastodon and plemora advancing this view a few years back, to an initially frosty reception that’s since become a grudging “nice to have but hard to add”.
My recommendation was much like MX records for email, so you can use a hosted server under your own identity.
There are people who want to add distributed identity to ActivityPub. It was left out of the spec but there were things left in to make it possible to add later. That's my understanding from a distance, anyway.
I've been able to switch mastadon instances without any problems; most instances seem to handle whatever activitypub machinery transfers followers.
So as long as both your source and destination support account transfers, you can usually switch and even seamlessly bring along most of your followers without them noticing.
No idea about your admin question. All bets are likely off with a bad admin. If you want actual cryptographically guaranteed communication, that doesn't exist in a usable form (except for Secure Scuttlebutt, and that's reeeeally stretching the "usable" part)
That doesn't actually work, though. Old links don't update or forward to matching instances of your toots on Mastodon. They're isolated. It's a bad experience.
That's a good point. It would be nice to have a streamlined export flow that rewrites your links for you.
(It's technically possible to edit the links in the posts you exported yourself before importing, but technically correct isn't the best kind of "correct")
Yes, Tim-Berners Lee led the Solid project[1], which reverses the client/server identity and data model. The user will store their own data and the service provider can only access it under the policy set by the user.
The promise is that one can not only transfer the identity and all personal data across instances of a single service, but also across different services (imagine from mastodon to Lemmy).
Secondly, signing every message wouldn’t be impractical at all, I don’t think. We’ve had the technology to do this for a long time and it’s very simple. What we don’t have is good key management. For average users, this would have to be something provided by their devices (phone or the Secure Enclave in your Mac or whatever) - managing keys and the web-of-trust shamozzle are the main reasons why encrypted email for everyone never took off.
Not OP but I want to point my dns at a host and have them handle it.
You can pay for that service, but you have to administer the instance, and it’s not able to reuse the servers RAM for multiple domains; it’s not like email where spam management is built in.
The federation is opt-out, so by default an instance will accept any federation request. You only block bad instances after the fact (or use some kind of shared blocklist)
The main problem with the fediverse is that none of the people I want to read, post there. And they never will, because they are disparate sociopolitical demographics and the fediverse by design keeps them in separate instances that I at some level need to think about.
The majority use-case requires centralization, which is subject to the network effects that constitute 95% of Twitter's value. Great that it works for you and some others, but it cannot work for most.
I tried it but I just can't get into the flow of things, it doesn't feel like a lot happens during the day, but maybe i'm on the wrong server? I just want to expel my bowels and doom scroll bad funny memes
> it doesn't feel like a lot happens during the day, but maybe i'm on the wrong server?
We are oriented to think that way after ~15 years of the algorithmic engagement-maxi world of Twitter. It always looks like there's a lot happening all the time but look deeper and it's a bunch of people offering their weak takes on hot topics to build their brand.
What was the last thing you remember being must-see sfuff on Twitter?
> We are oriented to think that way after ~15 years of the algorithmic engagement-maxi world of Twitter.
I never cared about algorithmic engagement.
Before (and during) the engagement Twitter:
- has everyone you needed there, centralised
- has search, where you can find people and topics you care about
Mastodon has none of that: you have to know which server to join and how to find people and topics. Centralization always beats distribution in convenience.
You may not care about algorithmic engagement, but that doesn't mean that the content you are looking is free of the incentives created by said algorithmic engagement. I use Twitter search too, but it's full of hot takes, because that's what the network rewards.
It's kinda like the "I don't care about politics" stand. You might not care, but the institutions you interact with every day certainly do.
> What was the last thing you remember being must-see sfuff on Twitter?
The Russia circus last weekend made for some pretty good near real-time intrigue. That being said, I don’t care what crazy thing is happening…I’m not creating an account to hear what’s being said on “The Global Town Square ™”
My experience of it was actually opposite. I first started from Twitter, trying to piece together something from the chaos of tweets, but then I went to an actual news site which had a nicely packed timeline with latest action and had more accurate and more up-to-date information.
In theory, Twitter should be that real-time news feed from these kind of events, but it doesn't actually work. Signal-to-noise ratio is just very low.
How does fediverse intend to pay for server/developer cost? For new technologies many smart people work for free as long as it excites them and when it just comes to maintenance and fixing bugs it wouldn't be cheap for any technology with so many moving parts. Also, early adopters donate with much higher probability than when the masses arrive.
Coming of age in the late 90s/early 00s we had plenty of forums to choose from, hosted by hobbyists, with nary a monetization scheme in sight. And this was in the era when the tech was far less accessible and the hardware far more expensive. Sure, maybe a modern $5/month VPS running basic forum software isn't going to handle 100,000,000 active users, but it sure will handle 10,000 active users, and that's more than enough to have a healthy community.
(Note: I'm of the opinion that fediverse-style federation in the context of forums is merely a nice-to-have; the web is already naturally federated, and people should not feel bad if they want to save money/tech complexity/administration complexity by settling for ordinary self-hosted forums.)
This is specifically why I call out the federated model as a nice-to-have, not a requirement. ActivityPub is way, way more demanding of CPU and transfer than a simple forum, and as a result it's extremely difficult to self-host at scale. You can easily service 10,000 daily active users on a VPS serving lean, statically-rendered forum pages.
Is there a reason for this, though? Need to be able to iterate on features quickly? Maybe not being able to tackle various complexities with the total available resources? Or maybe federation is just inherently expensive?
Why couldn't we have an alternative written in a more performant language/runtime with maybe things like lower quality images/videos or something?
Because performance was not a concern when it was designed - or it could be that it was designed for small communities, and therefore not possible to scale-up cheaply. One of the problem is the caching of pictures from the different instances connected (if I remember correctly) which makes the data storage requirements go up very fast
The big issue with hosting forums and the like is trying to keep the bots at bay. I have seen very small forums get over run in next to no time. And putting in bot checks leads to frustration with the users.
Good point, my implicit assumption is that, unlike the classic forums of my youth, forums in the post-LLM age will want to adopt the "tree of invites" model (e.g. how lobste.rs does it) rather than allowing unrestricted write privileges (read privileges can still be public). This creates a localized web of trust that will be mostly manageable at medium scales; ban or revoke invite privileges to any users whose invitees turn out to be bots or sockpuppets.
It's still at the early days, so give it some times. But there are already some lively communities and, IMO, they are generally better in terms of quality since Fediverse is more niche and has higher barrier of entry.
This. Twitter is doing what they can to drive people to mastodon. I've held off closing my Twitter account but I need to get better familiar with mastodon. I was wondering if there are accounts like NWS <location> (weather updates) over there, or so they plan to have some soon. Also from brief exposure, servers like mastodon social reads like left wing echo chambers which is also cringe.
The main reason is I followed a lot of scientists in my field of research who left the platform. Plus there's been subtle (and some not so subtle) changes to the algorithm and the software.
Most of the people I followed before were clearly left wing. After Musk takeover a lot of them left the platform. Plus the algorithm now pushed more right-wing content in the home page. I wouldn't mind if it were real people discussing valid talking points. The problems are 1) they are all coming from blue check mark accounts, 2) most of it are clearly misinformation, and 3) you can tell most of these tweets and replies are troll and bot accounts. It's just annoying.
Musk boosting his own tweets in the feed was annoying. Had to unfollow him.
I use Twitter via mobile website, and it breaks more frequently than before.
Overall, it's become like Musk's other product, Tesla. It over promises and under delivers. It's not reliable anymore. As a 2x Toyota owner I cannot stand products that are results of crappy engineering. So there you go.
Edit: one more thing: it used to be that I could go to the trending hashtags and get latest news in a second. It's not the case anymore. Case in point: yesterday France was trending. I saw the tweets and got the impression that some member of minority community has committed mass stabbing or rape again. Because the Twitter results were brigaded by right wing blue check mark accounts spewing anti immigration propaganda. It was not until I read a BBC article that I realized what happened was complete opposite, police executed an immigrant at a traffic stop.
Twitter has lost almost all of its core values under Musk. It's just sad.
The internet is most definitely not fine. There is an incoming tsunami of chat gpt generated bullshit that is going to make most open discussion sites more or less useless. Twitter requiring accounts and Reddit shutting down apis are both related: chat gpt et al are a threat to the social media business and ironically made possible because of the social media business. TBF I think we should all be exercising extreme (even more than usual) skepticism on any discussion sites any more.
Social media companies are acting like a drug user who was getting their dope for free but now has to turn tricks behind the dumpster. Easy money (aka low loan rates) has dried up or much harder to justify so companies that have used their user population as a means to profit are realizing they need to charge money for things like blue check marks or API usage when all the VC's won't give them a hit anymore.
Publicly free content from users devolves to garbage content. I think the Chat GPT effect is they're realizing its easier for companies/entities to generate garbage that is at or exceeding the intelligence of comments by actual people (a low bar). Sure there are pockets of usefulness but this is tiny amongst the firehose of garbage.
If all that is publicly available on social platforms is just garbage nonsense, people will just stop going if any barrier is thrown in front of them. The internet as a technology stack is fine. This is how social media dies (hopefully).
A potential saving grace: I bet within a year or so it will be easy to self-host LLMs that are easy to fine tune and run. Then there will be a few open source tools that you can use yourself, privately, to capture your level of interest while reading, and periodically make a reader/summarize/filter agent.
This is not scary if people can fairly easily run it all themselves, keeping their data private. It would help wade through crap, and there is some irony in using LLMs to have personal filtering and summarization.
Compared to future versions of ChatGPT, Bard, etc. the models that individuals can self host will be much weaker, but I think that they will be strong enough for personal agents and eventually be cheap to run, and affordable to fine tune.
Sounds to me like the Internet is, in fact, fine. It's only those "open" discussion sites which are having trouble.
Those sites never fit my definition of open anyway (free, permissively licensed technology and content). The ones that do are smaller, aren't a monoculture and seem to be pretty untroubled so far. No one wants to scrape the little Mastodon or Lemmy instances or other small community sites I pay attention to.
Big deal if something is a threat to the social media business. The social media business is a cancer which should be destroyed anyway. Go outside and engage in real socializing instead of the depression-spawning, teen-girl-murdering version peddled by Zuckerberg and Musk. It's much better and once you change your habits you'll never look back. Maybe it has something to do with all the vitamin D you get from being outside.
If anything, nature is healing. I’ve noticed at least 1 community return to forums due to all of this (https://mholdschool.com/), and while unfortunately AFAIK there isn’t any good FLOSS software for it, it’s certainly a start.
Discourse is going to pull the same shenanigans as Reddit and Twitter, you can be sure of that. No one is going to host millions of users for free, forever, they'll all come around to get their investment back one day.
Yes, the respective projects themselves. If you can't trust a project not to fuck over its users, why are you so concerned about the hosting of their discussion platform in particular, rather than just about everything else?
Do you think self-hosting means "it's free to host"? Do you understand someone is paying the costs of hosting, and that someone can do whatever the hell they want to recover such costs?
usually those costs, for a specific community, are not very high. not sure about discourse specifically, but you can serve thousands of users for relatively cheaply.
Yeah. Honestly, at this point you have to think the ketamine isn’t being microdosed[0], or the whole Twitter escapade is an intentional op to burn down an account independent forum that has frequently been a source of pain for those in power.
I suspect the later. We’ve seen billionaires do it countless times.
Elon is not great at engineering things, either. The main thing that he’s great at is self promotion and convincing people that they should give him (even more) money.
Nah, how many people are using Twitter without being logged in compared to how many people legitimately change every link they receive to Nitter?
I used the 'redirect to nitter' Firefox extension and Android app but it got quite unreliable and nobody else that I know uses nitter at all. I think Nitter users would be a tiny, perhaps even immeasurable minority compared to casual readers that now are incentivized to either log in or fuck off (but... FOMO).
I didn't mean nitter _specifically_ but rather all forms of alternative/anonymous UIs for twitter (that strip all of the engagement/ad/tracking stuff from twitter.)
Of anything I suspect Elon saw what happened woth reddit and had a "wait, we should do that!" Moment.
Bingo! It's only a matter of time another service takes over. I would be extremely surprised if at any given time there wasn't at least two startups in the dark trying to be the next twitter. Just waiting for the right moment for a large group of people to get pissed off at twitter to launch their service to the public.
Wait until you realize that highly centralized businesses are a feature, not a bug.
We've BEEN through federated platforms before. We've even been through PROTOCOLS before. They're all horrible. The successor to any platform that currently exists will have slight improvements to what already exists, and that's IF they're able to do so.
I don't have a dog in this fight, but I do have over 30 years of being around social media platforms on the internet.
> It’s been the primary organizational mode for the last 10,000 years.
For most of human history, most businesses were small ma and pa shops operated by a few local people. These days large business chains are the norm. You could say that centralized big business killed the decentralized small ma and pa shops.
As the saying goes, the market can stay irrational longer than you can stay liquid - everything eventually falls, but Twitter's not on the long side of "eventually" here.
The key here is that the environment of near-zero interest rates these services proliferated in is over, so there is a drive to wall up and monetize their content more aggressively. That will probably fail, because all value they had was in community interaction. Who would want to train an LLM on post-2023 twitter content?
Because Big Tech demands big profits. They can not exist in worlds where they can not have a monopoly or oligopoly.
Smaller companies and ISVs, on the other hand, will be better off if their market is commoditized. They won't have to spend so much to compete in R&D, they just need to find each the best way to serve their (comparatively) small customer base.
One is that centralized _business_ has certainly not been the primary organizational mode. You can talk about centralized _government_ (of whatever variety you'd like), but the distinction there is that the centralized government had some sense of itself in an ecosystem - a citizenry, a land, a future, etc. - and businesses do not.
The second is that centralized entities sure wrote a bunch of stuff _down_, but it's hard to say they were the primary organizational mode for any but the last 50-200 years - the reach of serious centralized bureaucracies has only really begun to match their propaganda in the industrial and now computer age. Until extremely recently, the actual effective reach of a centralized bureaucracy was a day's horseback ride - control degrades rapidly as one leaves the core. "Heaven is high and the emperor is far away", as the saying goes.
Edit: With regards to the second note, "Against the Grain" by James C. Scott is a solid read.
It's not centralized businesses that inevitably fail, it's businesses that become top dog that inevitably fail.
If you own a company and want it to last through the ages and you aren't literally the only guy in town, never become number one. Aim high, but don't hit the top.
The same can be said for countries and practically any organization or group. You stay an underdog if you do not want to ever fail.
This doesn't make intuitive sense. Are you sure you're not seeing the results of survivorship bias? Or is there a mechanism in place that kills top players?
It's because once you're top dog, you stop aiming high and start maintaining your top spot. You stop being ambitious and innovative, instead you start being anxious and wearing rose colored glasses.
That leads to complacency, corruption, and delusion, ultimately leading to failure.
Everyone and everything from mundane individuals to megacorporations and empires have all fallen from grace once they became top dog. No exceptions.
If you want to last, aim high but don't become top dog.
To paraphrase Gilmore, “the net interprets [mandatory login and other access fuckery] as censorship and routes around it”
If Twitter locks out more readers, people will stop posting and move elsewhere. If Reddit ejects the mods that made it successful, communities will evolve elsewhere.
The forest will regrow and different paths will form, routing around the dying patches.
This is true of any medium in any free society. The net has nothing to do with it. It certainly isn’t capable of interpreting some website action as censorship. It’s not sentient. And there’s no dynamic network routing/damage at play here. It’s just people going somewhere else.
I have a prediction that will make you happier:
This is a temporary thing, that will generate a TON of press (outrage ; praise by the fans at the amazing bold strategy move) and will also generate a TON of signups right as there is a wave of people leaving Reddit.
And then it will magically open back up.
(More press)
And that's the story of pretty much every one of the outrageous/bold/brilliant/terrible strategic decisions you've heard of since the Twitter takeover.
What's most amazing is that it works everytime, I'm surprised there isn't an Onion copy/paste article about this each time.
It’s a gigantically dumbass move that’s killed off all amateur creators and consumers. My feed is just filled with full-time content creators churning out 1/20 threads that are consumed by other full time content creators.
I've been meaning to make a Twitter account since I follow a few accounts for some games that I play.
Between Twitter not being owned by a loon anymore and finally a reason to overcome my laziness, why not?
And yes, I know I'm playing right into Twitter's hand. Whatever, I actually like Musk anyway (an unpopular opinion that will no doubt get me flagged around these parts).
This internet started to suck a long time ago, but today was a red letter day.
Reddit's been circling the drain for years, but today is the day it truly crossed a line for millions of people at once (They killed Apollo and RIF).
Twitter's been getting rapidly worse since Musk bought it, but this is another red line.
We're not even allowed to talk about the influence of bots and astroturfers here. A popular post today was flagged within an hour, just for pointing out that a site claims to sell upvotes on HN.
I don't like it when the tech giants get in sync like this...
You can talk about the influence of bots and astroturfers...so long as you agree it's all one big conspiracy theory, like all the comments did on my post from yesterday [1], "The Gentleperson's Guide to Forum Spies". [2]
It feels like the "natural" development of VC funded websites - they offer a service that's heavily subsidized and losing money hand over fist to displace other services (I guess in Reddit's case it was self-hosted forums and similar?).
But that's clearly not sustainable, it's inevitable they'll pivot to monetizing the service - and that's clearly going to make it less attractive than the heavily-subsidized version people have gotten used to.
I guess the ideas is to lock the users in to the degree that the increasing monetization is put up with, and slowly enough there's no "sticker shock" of a previously-free service suddenly having a price.
I'm constantly amazed people are surprised by this, isn't it obvious that tying to a loss-leader service isn't sustainable?
The bigger problem is the plan was basically infinte growth and was only possible due to 0% intrest rates.
The last 15 years has been a weird fever dream of free money, now that intrest is a thing again suddenly the infinte spending expansion and figure out profitablity later model is no longer sustianable and reddit twitter google meta ect suddenly have to actually make money again.
Basically the internet everyone has been used to for 15 years is dead as the reality of debt suddenly resumes.
Expect things to keep getting worse or revert to the old version of the internet of scattered low power sites and forums.
Frankly only microsoft is really the only one that has a somewhat sustianable model for an intrest rate enviroment.
> Expect things to keep getting worse or revert to the old version of the internet of scattered low power sites and forums.
This is actually the most mood-lightening comment I've seen on this matter. A return to the internet of 15 years ago doesn't sound so bad to me. (Of course, the mood darkens again when I remember that it won't really be that, because, e.g., that internet of 15 years ago couldn't handle the bot-spam of today.)
Reddit didn't need to be heavily subsidized. Old Reddit was open source, had community-built apps, and could have been run indefinitely with a handful of employees and Reddit Gold. Like a Craigslist or Wikipedia model.
Instead with their VC funding they spent $$$ to introduce things like NFTs and TikTok scrolling, which nobody asked for, but it burned through a lot of cash.
HN doesn’t really have a business model so I’m not sure how much it can be corrupted. I guess if YCombinator ever gets tired of paying the bills , but I’d imagine having a majority(?) of startup/tech employees visit your site almost daily is quite good for them in indirect ways
I assume that if HN ever caused them any serious PR damage, they'd pull the plug that day. It's always been made clear that it's a single-server site sitting somewhere that was written as a hobby a long time ago. That kind of nothing cost they're willing to take on indefinitely, but not any serious bad media cost. I've always felt that was the reason for the heavy moderation, especially as compared to the anarchic early days. Even with the salaries of dang et al. expenses are probably a rounding error.
That's not independent of the moderation, though. Topics that invite heated discussion but aren't absolutely necessary to talk about on HN get nuked very quickly. If it would be absurd for it not to be discussed here, it gets a pinned note from dang telling everyone to behave, and gets carefully monitored to make sure it doesn't degenerate into a riot.
It’s effective because in this instance their interests align with their audience’s, which is pretty much an ideal situation in such a capitalist economy. Also, I don’t know how much HN costs, but I cannot believe it is disproportionate in the PR and communication budget of something like YCombinator.
Bingo! Being open to access, but heavily moderated, is the perfect spot for them. HN is essentially perfect for it's use case and is unlikely to change soon.
I'm cautiously optimistic about Lemmy. Anyone can spin up an instance, so it's decentralized, but instances are connected, so there's community.
It may still be rough around the edges, but to me it feels like the spirit of the old phpBB forums combined with almost 20 years of lessons learned from Reddit.
<rant> Not responding directly, just piggy-backing for lack of a better place to put this comment.
The problem with Lemmy is that one gets sent to some place like https://github.com/maltfield/awesome-lemmy-instances, is immediately confronted with a ton of weird links like "butts.international" and "badblocks.rocks", what even is this? And about 100000 other servers just named "lemmy", "notlemmy", and "lemmy1". So you click a few at random optimistically, then get hit with login page, or a server error, or an apparently empty test-server. You begin to think you're being pranked, like am I supposed to brute-force click like 50 things to find something that's not a joke? Maybe you go to https://join-lemmy.org/ and it says "After you create an account, you can find communities", so great, it's inaccessible anonymously, the same as twitter. You go to https://lemmymap.feddit.de/ and after 15m of page-loading get a hilariously useless cyberpunk-looking word-soup where you can't click any links, much less search for topics/communities (btw there are 2068431 running instances and somehow butts.international is still front and center in my cyberpunk view)
Finally, by ignoring recommended tooling and just using google-search I found a community relevant to my interests, but it has pretty bad content and a whopping 1 user/day. Another google search trying to find a certain topic, I find one, but it has only 3 total comments, and I could not tell what month/year the posts were added.
So, clearly I don't really know what I'm doing here, but this stuff is ridiculous. As long as we're crawling 2068431 instances why don't we look at the communities it hosts and the volume/recency of traffic? At least filter totally empty stuff and/or make it easier to get all the test instances in a sandbox! Discoverability is so bad that I can barely get to the point where I'm considering usability / content.
You're making a very good point. I looked at lemmy stuff before but I moved to kbin instead. It has a more familiar interface (to reddit) and it is federated with lemmy. This all sounds good and it is. But even there I basically have no idea what's going on. It has more content than the lemmy instances you visited but every once in a while when I remember to visit I only look at whatever landing page I configured and can't figure out what's kbin, what's lemmy, what "magazine" I am looking at etc. To be fair, it's already a pretty good product and it is likely to get a lot better. That's exactly why I keep trying.
As someone who signed up for Lemmy and is planning to replace my Reddit use with it, I hear these points loud and clear. You also make a good point about Google search and how bad it’s become - I see so many stories of people adding “Reddit” to their search in order to get any decent results. This is the natural result when you have every business paying people for SEO and trying to game the system.
Between account walls and search’s indexing problem, it’s become very hard to find small to mid sized active communities on your own. In fact this problem seems to be something people are trying to solve in Reddit communities via related subreddits on the sidebar.
So having gone from using search engine’s to crawl for relevant content that was out there, people are now creating content specifically to end up in Google’s search results - destroying the value search once had. Indicated by what people have done on Reddit, and these discussions about finding alternatives, it seems we are well on our way back to webrings. I welcome this.
Good example of irritating comment that led to the odyssey above. What you say also appears to not be true. The correct assertion is maybe: If you can find an instance, and if the instance is configured to allow anonymous, then you can browse communities. Since nothing is ranked or searchable, then if you're willing to do that for N instances and M communities, enduring server errors/login screens the whole way, maybe you can find decent content after weeks of brute-force labor. This isn't practical for someone who just wants to spend a few minutes finding a replacement for /r/math and /r/physics or whatever.
For the short term at least, since discoverability is so broken, I think those who want to advocate for Lemmy will be better served by just linking to content or curating indexes of active communities. It's not that useful to anyone if the focus is always about pretending everything is fine, or presenting prospective users with totally useless machine-generated indexes where we cannot tell the test-servers from production.
IIUC it's federated,not decentralized. Still pretty good but if a server drops offline it will be pretty inconvenient. The communities on that server will be dead.
Matrix does better as the rooms are decentalized so can continue even if the creating server drops offline. But user accounts are still only federated.
Lemmy.ml's admin is pro chinese government and actively censors comments that are critical. What that means to you is your decision, but I want to make people aware before the mass migration date arrives.
Lemmy's team is very politicized, but even then it took significant pushback to change their minds about an issue that the community was decrying for reasons that were almost entirely technical.
It bothers me a little bit that having a strong stance against intolerance is seen as being “politicized.” That should just be normal and expected behavior.
Maybe they were abrasive in initially fighting the request to make technical changes to the slur filter, but hey when you ask for free enhancements to open source code you either do the work and provide a pull request or be prepared to be told no.
I empathize with their concern about becoming another Voat or Gab. They want federation but they don’t want a Wild West.
The problem is that the stance is incredibly shortsighted and in a way bigoted itself. Take a word filter that contains some regex for n**a. They are saying you should never use slurs and this word in particular in public discourse.
So the word above word is used in lyrics of a music genre with predominantly black musicians. In addition to saying we don't want our software to be used by racists, they also say "we don't want our Software to be used to discuss certain kinds of black music" (arguably a racist stance just by itself). Talk about unintended side effects.
yes, this is one of the trade offs of any system built where one must decide between human moderation/curation vs automating moderation/curation.
if automation is chosen there will absolutely be situations where perfection is impossible. if human’s unparalleled ability to see nuance is chosen then the cost scales along with the amount of information.
the fact is, if we want a community and we want to keep signal above noise, we will need some form of removal of spam, child porn, racism, etc…
automatic tools can’t nuance as well as humans.
then human mods start nuancing and someone will point at stuff and call it biased.
> It bothers me a little bit that having a strong stance against intolerance is seen as being “politicized.” That should just be normal and expected behavior.
It did not seem to me a politicized discussion but a technical issue with filtering using hardcoded blacklists that are just too prone to the Scunthorpe Problem. Perhaps because too many people in the USA despise the mere existence of other languages :)
I think we have to remember that this isn’t a commercial product, it’s a small project. They had a quick and dirty solution and weren’t willing to abandon it but also weren’t initially willing to put in the time to make a more robust solution.
This seems to be inaccurate. When I go to join-lemmy.org, and click join a server, the first servers on the list are at least semi-randomized recommended servers. Every time you refresh the page the selections change.
As far as the “popular” list, which is placed below the recommended list, lemmy.ml doesn’t have any special privileges there. It just happens to be the most popular. If something becomes more popular it will go on the top.
There's nothing stopping you, the source code is freely available to edit when you start up your instance. It would probably limit the appeal of your instance to many people and maybe some very ideological smaller instances might defederate, I doubt the other major instances would care much since only those signed up at or browsing through your instance would see the ads.
I see absolutely no reason why an instance might not decide to fund itself on local ads. I see no reason why you couldn't choose an ad-supported or non-ad instance
Forums used to be ad supported, nothing particularly wrong with being ad supported. Problems occur when your investors expect 10x return on something ad supported.
But to have something pay for it self. I'd rather not lose money on it
Actually, there is something wrong with ad supported platforms. Advertisers start imposing restrictions on the actual content, or the owners of the platforms enforce restrictions pre-emptively so it never arises.
I was on a forum, and the kind of language and even topics for discussion were severely restricted, partly because of advertising.
I mean I consider this a huge win: delete your Twitter account and never again will you be tempted to go read a tweet. If only I could set an anonymous expat cookie for all the services I've left behind letting them know "No, seriously: I left and I'm never coming back. No reason to track me, show me your content or ask me to login." Where's my restraining order cookie telling Facebook to fuck off outta my life, never to return?
Was using Fritter for Twitter and Infinity for Reddit. Both apps allowed local subscriptions without forcing a login. They were perfect. Both now dead in the water for me.
I’m so jaded with the internet at this point. Most phone apps and games are a microtransaction hell. Most social media apps are a race to the bottom with clickbait. Every website is littered with ads and popups and cookie banners.
Time to go outside and forget that the online world exists.
There is any believable amount of content being made where the value is so absurdly low, I welcome this change. For everyone that wants to setup a copy/paste version of a CRUD app or YouTube channel, that is a ton of time and effort being wasted. I’m not saying we should be focused on solely optimizing everyone’s time and efforts, but it’s clear we have tipped the scale too far with how much time and effort is being dedicated to bullshit.
If we as a society decided to channel these efforts into building infrastructure improvements and homes, I think this would help a lot more. I understand the biggest problems in that respect are legal and cultural, but I can’t help but feel people have tried nothing and are all out of ideas.
I have Starlink, which gives me a US IP when I connect to it, and I was surprised to see the amount of ads people there are subjected. Most don’t do business where I am, so their free tier is effectively without ads for me (except twitch. It choses to show me US ads for some reason).
Reddit's Eternal September began no later than 2018 when Tumblr banned porn. What's happening now is that it has hit an apparent growth ceiling (most of the most upvoted posts are from more than a year ago) and the owners have realized that they have to make it profitable now or never.
As long as the site is growing, it doesn't have to be profitable. But when the music stops...
I think the big problem with profitability comes directly from why the userbase grew so large to begin with. People use it as entertainment, and are uploading content that is expensive to host. Video and images are magnitudes larger than simple text and links to that content. If Reddit didn’t take it upon themselves to host media, they wouldn’t be in such a crunch. They also wouldn’t have grown so large, true, but there was no question of Reddit’s sustainability then. With mainly text and links, weathering the slowdown in growth storm would be easier.
> This version of the Internet is starting to suck. :(
Totally! The internet was better before pay walls / auth walls.
I get why we're here today, and I get that the last phase was just about acquiring an audience, and getting people hooked, and now this part of getting everyone to pay was always the plan, but this part really does suck.
Just feels like all the services lined up to start shitting on users at the same time. Netflix, YouTube, Reddit, Twitter, NYT (and all the newspapers really)... you can't watch Amazon Prime without having 300 "buy now" buttons in your face.
I remember seeing a documentary way back in 2000 about the internet that said something like "the internet is freely accessible now, but some people believe eventually pay walls will begin to block access to more and more portions of the internet." And I thought how ridiculous, that will never happen, information wants to be free!
Well, looks like I was only partially right. Most access is still "free", but at the cost of enshittification.
Ah, the F2P (free-to-play) model. Indeed I’m surprised that microtransactions and pay-to-win type dark patterns have mostly not been adopted on the internet at large. And loot boxes! Can’t forget loot boxes.
If P2P micropayments could somehow have succeeded, then a different Internet could have been possible. Tipping content creators directly is impossible without megacorporations taking a cut, be it Apple, Paypal, Patreon etc, and their unit economics work better with recurring payments, which lands us in subscription hell.
One would almost be tempted to ask for a cheque in the mail like in the old days.
P2P payments/transaction media have been on the way out for decades due to the State's interest in controlling the financial transaction medium as tightly as possible.
The database has doomed us all! For it is the Seed of all Evil in the hands of the Wicked! ...and arguably the Good, but misguided!
It doesn't solve it at all, I am talking about real money you can spend in a store, not tokens that need to be converted through an exchange into cash each time.
There are stores where you can pay with cryptocurrencies. That said, GP said "almost". We will see if it ever reaches the point where this word will not be needed.
The reason why you can't spend it at the store is because the store doesn't accept it. The reason why the store doesn't accept it is because of the aforementioned scaling and complexity issues.
I'm at least glad that people will start looking into the alternatives.
The next lesson they need to learn is TANSTAAFL. Nothing good can come with an internet where publishers are paid with eyeballs. We need to rescue the idea that "voting with your wallet" is the best and fairest way to have quality content.
Somewhat agree, though the income disparity across nations (and even within) makes pricing somewhat more difficult- but I agree with the spirit of it having to be non-free.
also killed my irc bot that scrapes tweets to display them. Imo It won't help twitter to have no free read API calls, people won't click on every twitter link just to read two lines of text. I'd only need ~30 a day but I'm not paying 100 dollars a month (?!) just to read a few tweets.
Years ago I was brought to twitter compared to Facebook exactly because you could read without being logged in.
After a few years it had become a hellish place with lots of flames and arguments, but it still had some value.
It became clear that my engagement was mainly to discuss with random people about things knowing they would never change their minds (neither would I) on things like Covid vaccines.
It was a huge waste of time, but I found it out that surfing it as non logged would amore allow me to read without being able to reply to the most stupid comments. Some sort of read only Twitter.
Now that it has gone, Twitter has irrelevant.
Ugh, what an eventful time of social media this has been.
First Twitter API, then Reddit API, so today Apollo and many more Reddit clients shut down, and now Nitter. :-(
I'm happy Lemmy is kind of taking off. I think it's helped more than Mastodon because it's less realtime/feed focused and slower paced. It also doesn't require you to form a friend circle to benefit. Instead, the community is waiting for you already. You just sign up on an instance and add your communities. Done. This helped me a lot, together with sites like https://sub.rehab
I really like lemmy too. I think the biggest issue is that people think of Lemmy itself as the replacement of reddit.com. But what makes more sense to me is thinking about Lemmy as a tool to build separate websites that are each a replacement for reddit.com and that these can interoperate with each other to grow based on the local users interests. I think the biggest hurdle is figuring out where to create your first account... it's just not intuitive and of course the more established sites shut down signups during mass waves as an anti-September protective measure.
I ended up starting at programming.dev because someone on HN mentioned it and it at least seemed to have a focus and also wasn't a ghost town. And that was pretty good but I've also joined beehaw (takes some time) because I like its size and decorum and generically would choose to get on their side of a defederation. And after I'm starting to understand how this whole activity pub and defederation and federation works, I really am optimistic about it.
I think somebody needs to build something that's a crossover between GitHub pages and activitypub that sort of behaves like discus and integrates with Lemmy/kbin/mastodon. So that blog writers can have comments at their own sites again and they can integrate together to grow organically. I haven't quite pieced it all together, but I sort of see that could grow as a replacement for what we lost with Google Reader and the loss of blog commenting communities.
Yeah, good point about instances being communities! It’s like how the Star Trek one did it and my mind boggled when I realized you could (and someone has done so) make a national Lemmy _instance_ rather than just a /r/mycountry. And then everything there is localized! So you basically have a social news _site_ in your language that can federate with all the rest.
Of course, this goes for any major interest category but it just hit me the hardest so far to realize this.
Another cool development would be a science-oriented Lemmy instance with lots of special purpose sciency stuff.
Viewed like this, the sky is the limit for Lemmy and it could have potential to grow a lot!
> An instance dedicated to nature and science.
> The main focus of this instance is the natural sciences, and the scope encompasses all of the STEM fields.
> I think that's the biggest hurdle is figuring out where to create your first account.
Agreed. I think the barrier would be lower if I knew I could migrate my identity to another instance if the first one became sketchy or shut down or de-federated.
Instead AFAICT I have to choose not just what community to join and where the content will initially live, but also which of these random groups to trust with my identity indefinitely going forward.
Maybe we need some sort of self-identifying system.
Like SSH keys, where you manage your own identity and then share a public key to each instance that identifies you to that instance.
Like an identity client you could self manage if you wanted to. Make it optional, portable, and transferable. So you can choose to let a server host manage your identity, or migrate to a self managed identity.
I've seen discussions that Mastodon has a way of migrating accounts. I don't know if that's a Mastodon specific thing or at the ActivityPub level. I don't think it migrates the content but I'm not sure. What I think it does is notify followers of the migration. I'm not sure anything like PKI is necessary.
Conceptually a planned migrations should have a period of concurrent access to both the old and new accounts and it should be easy to publish a handshake to confirm the migration to followers to update contact info. That's my thought anyway. Something like keybase (does that still exist?) could also be used for similar sorts of proofs.
The way people used to handle this on Reddit is people would send a message from their old account saying "hey XYZ is my new account" and that seems sufficient.
I'm not sure about that entirely. It seems like kbin can federate with both mastodon and lemmy. Lemmy and kbin can federate with each other. But I don't think Lemmy and mastodon can right now. I don't know if that's deliberate or just unimplemented. I will say the kbin/mastodon interactions just seem... strange. Like you see mastodon users but I don't know why I wouldn't just use a mastodon client. But I haven't spent a lot of time directly inside kbin. I prefer the lemmy interface so far. People have described it as lemmy being like old.reddit and kbin being like new.reddit in feel.
Indeed, I thought HN of all places would understand that the last 15 years were a bubble of zero interest rates. Now, companies have to be profitable or die.
It always irked me that public institutions embraced Twitter as a primary means of communication in many cases. It never seemed right that a private company was being put in between public functions and the the public which depends on them. Not to mention, since I live outside the US, a private company in another country. I even wrote complaints to one local public body to ask them to set up a communication channel that wasn't controlled by a foreign private entity. Of course, they laughed at me and I went away like a good citizen.
It's hard to map this onto my framework of "reasonable paranoia". Even while I felt uncomfortable about it, it never occurred to me that Twitter would actually cut off access. Now here we are.
Privatization is a thing beyond seemingly fundamental online services.
Local water systems in Guam are privatized, much to the chagrin of local activists.
Elsewhere, there's an article on the guardian just like yesterday about the impact of privatization on either the UK's or some locale inside the UK, for their water usage. Basically the water department is now the highest debt entity in all water departments and it's the one that's privatized.
Privatizing public data is a shortsighted thoughtless approach to public communication.
Electricity markets are a prime example of ideology winning over logic. In Australia, the eastern states have a privatised electricity market while Western Australia has a very limited market with agreements to hold a certain amount of gas fuel at a certain price. Currently the price of electricity is significantly higher in the eastern market than the "less free" western one.
In the UK, water (Thames Water), the country natural and fundamental resource is owned by a Chinese wealth fund and Canadian Pension funds. How could anyone think this was a good idea?
Yep, god bless our communist energy policy, while the eastern states were screaming about rocketing energy prices a year back, ours were stable because the electricity company is state owned and contributes profit to the public purse, and as you say a certain portion of gas has to be reserved for the local market.
Coming from the UK I don’t want competition in basic utilities like there is there. I don’t want to have to shop around for the best energy price every year, or to be at the mercy of the free market on pricing for the most basic of necessities like power and water.
The western Australian example just demonstrates why petrostates are wealthy - if you have big energy resources you can make stuff cheaper, surprise! And realistically all that's really happening there is west Australia is effectively imposing a tax on gas profits to subsidize the grid. There's no magic success here - just a redistribution of gas profits to electricity consumers.
I don't actually think the Australian grid is a good example of privatisation failure. There's little proof that we have meaningfully lost anything aside from the marching cry of the left.
> There's little proof that we have meaningfully lost anything
Did we gain anything? I ask in earnest, I don't know.
I can guess that the cost of running, maintenance, etc are now "not a cost of the state", but the cost doesn't just disappear, it was always on the consumer via tax or bills (or tax and bills, hopefully in a way that sums to the same cost!).
In theory, you remove government overhead. Government bureacracies are infamous for expanding without the requirement to make a profit as a constraint.
As it pertains to power, People tend to promote government as a means to make it cheaper - but this is sort of a fallacy - the only way the government can do it cheaper is if it's operationally more efficient to a significant degree. I don't see how a government achieves this. Private energy generators are usually not very profitable - the people making money were commodity producers, recently, not electricity generators.
There's absolutely no evidence of privatisation driving up costs in Australia.
It's the hysterical marching cry of young naive people railing against the ever-increasingly vague boogeyman of neoliberalism but the actual evidence doesn't back it up.
You talk about ideology over logic while demonstrating that exact same thing.
> The AER report contains no consistent correlation between higher bills and privatisation.
> The ABS index of electricity prices across Australia, showing movement of electricity prices over time, also doesn't demonstrate a link between privatisation and price rises.
> Whether comparing electricity bills, prices or the relative price index of electricity in each state, there is no consistent link between privatisation and what consumers pay for their electricity.
> Experts say the biggest influences on what people pay for electricity are costs of transmission and distribution. They say these costs have risen in recent years irrespective of whether the owners of the transmission and distribution networks are privatised.
A natural resource lieing solely in the hands of profit-driven private companies. Take a moment to reflect on the potential risks this poses for the average consumer, the consequences of placing profit above all.
Will you entrust your well-being to CEOs and boards whose sole priority is relentless growth and maximizing profits, regardless of the consequences?
Laws can only do so much to prevent vital resources from becoming unaffordable for the very people who deserve them. These companies, with no regard for your, the citizen's, vote or input, prioritize profits above all else. To them, it's just another business move, leaving the consequences behind as they move on to the next venture.
You can argue and consider other ideas, but the higher risk in the private side is always there.
> These companies, with no regard for your, the citizen's, vote or input, prioritize profits above all else.
And they are easily reigned in by the Australian Electricity Regulator, while governments owned businesses are not.
We recently had a price cap put on coal and gas prices, private companies had to eat a massive loss, government owned generators huffed and puffed until they got billion dollar bailouts from the rest of the nation for their coal guzzling power plants that should have been shut down years ago had they not been taxpayer liabilities.
There's simply no evidence of these things driving up prices. We have a huge government owned pumped hydro power storage project underway that has blown out from $2b to $10b in the spacce of a few years, if this was privately owned it would have gone bankrupt, instead more and more cash from electricity users will eventually have to be paid to fund it. It's costing 5x more than simply putting grid scale batteries in the cities and the government has sunk cost fallacy that it can't walk away from.
This is the problem with government ownership of electricity assets in Australia, politics gets completely in the way of good decision making and projects that should have failed long ago.
As I said before, where's the evidence, because all I see is ideology.
This is what happens when governments run electricity projects:
> He assured the electorate it would cost $2 billion and be up and running by 2021.
> By April 2019, a contract for part of the project was signed for $5.1 billion — and that doesn't include transmission costs, which will cost billions more.
> Who will actually pay for transmission is still being decided.
> "Someone's going to pay for it," Snowy Hydro CEO Paul Broad told 7.30.
> "The taxpayers will pay for it through your taxes, or you pay for it through your bills.
The current cost is $10b and the project has blown out to the end of the decade. No one is admitting how far they've dug or the status of meeting targets. The transmission bill is still up in the air but will likely be an additional $5b added onto household bills.
Snowy Hydro 2 was a scam from day one. It was created by a LNP government so that it could convince voter it cared about climate change. Once that leader was ousted the truth came out and the real LNP climate denial was there for all to see.
Also, the LNP have proved time and time again they can't build any public infrastructure.
Their Inland Rail project is another total disaster, a project wasting many more tens of billions and achieved absolutely nothing.
And how can anyone forget the failure that was the LNP re-design of the National Broadband; a design that moved away from fiber optic to instead use copper wire.
Why is it, despite having some of the largest LNG gas resources in the world, the Eastern states of Australia pay more for their LNG than customers in Asia?
Is it a coincidence that Western Australia (WA), a state with the most government regulation in regard to LNG exports also has the lowest LNG prices by a long margin?
In general WA, has the most regulated energy sector with the highest level of public ownership in electricity production and transmission, and by strange coincidence it also has the cheapest gas, cheapest coal and lowest electricity prices.
I'm asking anyone to provide evidence of privatisation riving up costs in Australia. It's simply not there. The most privatised state in the country has the cheapest prices, this is undeniable.
Put up your "logic" rather your ideology if you want to convince people otherwise. Downvotes don't count sorry :)
Prices are the cheapest in Victoria, with full privatisation of the network. Prices are also most expensive in South Australia, with nearly full privatisation of the network. No rational person can look at that and proclaim there is a correlation.
We have states with nearly all generation, distribution and transmission being government owned, we also have states completely out of the business. This should be a simple slam dunk to people who loudly make these easily proven claims and yet they never have any proof.
Prices are rising uniformly across the board, including in the heavily government owned states, which coincidently are the worst at rolling out renewables because they are protecting their fossil fuel golden eggs at the expense of the environment.
Two eight year old pieces don't reflect the recent changes in Australian electricity prices which is the period in which the most grevious examples of price hikes have occurred.
While interesting time capsules one wonders whether Lynne Chester holds the same opinions today or has updated the prices tables 2007-2014 with more current data.
Personally I'd look less at the month to month prices and more at the decade on decade projections .. what are the winning long term strategies for cost effective power generation with the "lowest bad for climate" emmissions totals.
> The move comes in reaction to the federal government's Online News Act, Bill C-18, which would require the tech giant to pay Canadian media companies for linking to or otherwise repurposing their content online
Wow that's a pretty interesting story. Intrigued to see how it goes. As a lawyer for a tech co I've always wanted to entertain a situation like this (small market is behaving so absurdly you simply leave it) but it's pretty rare. Good test case.
Something similar happened in Spain in 2014, when a local law would have forced Google to pay for linking or using abstracts. They shut down Google News.
Due to some revenue sharing rules that just went into effect in Canada, designed to prevent news from being absorbed by Facebook and never leading to the ads being seen on the original website, FB is closing link. Sharing to cbc.ca. People can go there directly, but eventually safety information being everywhere is a good thing.
The "revenue sharing rules" you speak of were a shakedown. Imagine if YC had to pay Tech Crunch for linking this post. They would shut down HN immediately. That's what they are requiring of FB.
Yeah except they aren't just providing a link, they are wrapping up the headline, a picture, and the first graph or two from the story onto timelines surrounded by their ads, which sends no revenue to the source. People don't click through. It just looks like "Facebook News". It's not that much different from a content farm.
> Yeah except they aren't just providing a link, they are wrapping up the headline, a picture, and the first graph or two from the story onto timelines surrounded by their ads, which sends no revenue to the source
Only to the extent allowed by news websites headers. Maybe this whole thing could have been solved by politicians understanding tech a little better?
> Maybe this whole thing could have been solved by politicians understanding tech a little better?
How often do we hear, on HN and elsewhere, people complain about laws they don't like wish politicians better understood what they are legislating? This implies the existence of a technological solution, set by technocrats who "understand" better. Whoever asks the question suggests politicians don't know better, offering that explanation without proof.
Also, for the Free Market enthusiasts out there, why hasn't the market solved this problem? What forces are preventing all parties from working out a technical and economic solution?
Imagine if HN just copied the first few paragraphs of the TechCrunch article and stole the pictures as well, completely cutting TechCrunch out of the loop.
The government of Canada is of the people, by the people, for the people of Canada. You're saying it's the people of Canada who are responsible for a business interest refusing to extract their wealth if it can not be done for free, and you're entirely correct.
Goodbye Meta and Google and other greedy foreign exploiters and don't let the door hit you on the way out.
> The government of Canada is of the people, by the people, for the people of Canada. You're saying it's the people of Canada who are responsible for a business interest
So they can never make mistakes and be blame free in any scenario?
> refusing to extract their wealth if it can not be done for free, and you're entirely correct.
Yes, now they can keep all their wealth with them. Why are they complaining? Why fret over this if extraction is being stopped by these companies shutting down link sharing?
> Goodbye Meta and Google and other greedy foreign exploiters and don't let the door hit you on the way out.
Yes, it is the foreign companies who are greedy and not rent seeking mega news corps who want $$$ for linking to them lol.
There are no large media companies in Canada, just independent journalism pure in heart and no commercial intent.
/s
In the Australian case Facebook acted in retaliation.
The law was about news media, Facebook shutdown a bunch of unrelated govt services pages in retaliation.
Facebook definitely deserves a lot of blame. Likely in this case too. I'm pro capitalist as much as the next guy but laws are by the people, if a business wants to extract money from our community it needs to play by our rules.
Facebook cutting access is like a badly raised toddler throwing a tantrum.
By this logic, shouldn't news orgs pay people in their stories?
> I'm pro capitalist as much as the next guy but laws are by the people, if a business wants to extract money from our community it needs to play by our rules.
Wait, if FB was extracting money, wouldn't FB shutting down linking cause more money to flow into news orgs? Shouldn't you celebrate this as it will reduce the "extraction"?
Why fret over this if extraction is being stopped?
If news orgs truly believe in extraction, they would be celebrating this shutdown in the streets.
> Facebook cutting access is like a badly raised toddler throwing a tantrum.
In the free world, we are allowed to choose our actions to some extent.
And if it's not Google it's Microsoft. Which is, and I can't believe I'm saying this, the lesser of two evils at this point. There's a 2003 me staring through a time travel portal absolutely aghast that 2023 me is saying something like this.
Microsoft has always been an apex predator, like a lion or maybe a hippo. It can end you in a single bite, but at least you know what you’re dealing with.
Google is more like a malaria carrying species of mosquito. Little bites that you barely notice, but in aggregate are actually much more dangerous.
I know the metaphor is a bit stretched but even in the late 90’d it was clear what Microsoft did. Google has gone from “don’t be evil” to “this is the definition of open source” to …
True, but they are widely known as being one of the most dangerous animals in Africa; number 11 on this list [0]. So you (probably) know what you’re dealing with.
Of course my point was that the mosquito, whose bite is far less “annoying”, is actually #1.
All big tech companies that store non-e2ee data are equally evil, because they all by law must make that data available to government spies without a warrant. (They know this, and they still collect the data.)
These same government spies run an international network of torture centers.
Every public school and government institution for at least the last two decades has depended on private SaaS companies for everything from recording grades, to managing school lunches, payroll, attendance and almost every other facet of education
It does beg the question why the public sector doesn't aim to create a public source software division for all of these administrative needs. Jobs program and all that.
Because it would be full of unique unpatched exploits, 20 years behind schedule and 10x over budget.
I wish, the US government, was like that full of decisive, well intentioned, intelligent boot strapped innovators but the motiff of government projects are things like:
One bathroom stall at build costing millions and years behind schedule
City trash bins costing hundreds of thousands
Airplane trash bins costing tens of thousands
And the list certainly Curtis go on those are just the recent ones I’ve read about.
I’m watching a government software replacement worth tens of billions and seeing the attempt to integrate is painful. They sure aren’t agile.
That's just it. Create a publicly visible repo of code for all of these administrative government softwares. Let the public weigh in. Create a contribution process. We're not talking state secrets. Just an quasi-open sourced government platform.
For the explicit purpose of my personal data not being siphoned off, owned, and monetized by 3rd party private companies via proxy interactions with the government (like, you know, public school) that are almost virtually unavoidable for most citizens.
You trust the competence of the government to keep your information private?
And I can guarantee you they are going to bring in high priced consultants to do the work because no government or board of education is going to ever pay software developers their market value and have them on their payroll.
Private companies (Salesforce, snowflake, etc) offer "government cloud" services where they are restricted by law (fedramp and others) from using your data for their own purposes. Do you not believe that is actually happening? I've worked on them myself.
It’s cheaper because an edTech company can create a piece of software once and sell it to many different school systems at a low marginal cost. That’s kind of how software works.
Yes for large corporations and governments that aren’t just working with Teams, they are working with Microsoft Office and SharePoint and want something that works well and is understood by their contractors. Teams is already bundled and integrated with their massive enterprise Microsoft contracts.
In a given month, as a consultant I’m working with clients that use Slack, Teams, Google Meet, Zoom, and if I’m initiating a meeting, Amazon Chime.
Unfortunately, we are living in a world where using private company's social media is the most effective way to communicate public announcement as lots of people are using it daily. I am not sure if people are going to install government social media app just to receive information pertaining to public matters.
At that point “just” normalize RSS feeds. They serve an even better job for none of the centralization. My state already sends weather warnings via RSS, and I’m sure lots of other things I haven’t explored yet.
On the other hand, public institutions have long been criticized for not communicating where the people are. Notices posted on their own website are unlikely to read by anywhere as broad an audience. Plenty uses newspapers, but even my grandparents get stuff from Twitter before the paper now, if just from younger people sharing it with them. I agree Twitter shouldn't be the only channel, but it is where the people are, or at least were.
If only we had a standard to make syndication of data simple, I mean really, really simple. It had to be so simple the standard could even be called Really Simple Syndication.
How does this help to fix the essentially non-technical problem that on long enough time horizons, and by long enough maybe 5 years at most these days, content that is optimized to provoke reaction ("engagement") outcompetes content that is optimized to promote contemplation, on any network, whether syndicated or not.
These days setting up a website costs $16/mo[0] and is so simple my 70yo father-in-law did it. I'm pretty sure most public agencies can find that in the budget.
well, it was. now we’re seeing these companies—who used as one of their primary selling points to lure in talent, “come help us make the world a better place”—in real time, one by one, we’re beginning to see their true motives and true colors come out as they begin to close up public access.
i think the real question is when, not if, we end up with public infrastructure.
It's worth noting that many government institutions nowadays have (often several) social media communications "officers" officers, whose only job it is to disaminate information via social media (twitter, Facebook...). Now you'd think that if they hire a person for these sort of things (btw keeping track of multiple social media account and monitoring relevant keywords is definitely not typical nontechnical user territory) they could train the person to update a cms as well.
What's harder: signing up for Twitter, or convincing the sysadmins in your medium sized government organization to let you update text on the site in real-time without change control for each edit? In a way that anyone nontechnical can do so securely and publish to RSS?
Or Remind, or ClassDojo, or Parentsquare, or whatever our school district goes with next year. I think they could all do SMS delivery, but none of them got it quite right. The apps are all buggy too. Various updates are often squirreled away on Twitter or "$schoolname Parents" Facebook group.
I think I remember suggesting RSS to them as an option. Utterly technically trivial. If they'd done that and then syndicated it out to Twitter etc, they could have served everybody.
NZ government was using Facebook almost exclusively to do that during Covid. If you didn't have a Facebook account you were basically stuck with TV news or radio. Online news sources would only link to the Facebook post.
Public institutions should have known better than rely on a private whim without any kind of obligation to make their feeds available.
RSS is piss easy to configure, they should have done that and encouraged people to use their RSS aggregator of choice for important things.
It's not "fake news" that you now need to be logged in to see tweets. Whether or not this is truly temporary remains to be seen. But we now know this is something Twitter is willing to do, even if they undo it.
The article itself is well over 6 hours old. While you may technically be correct about the fact that Musk's tweet counts as comment, an article that has yet to be updated should be called "now inaccurate", not "fake news".
The way you've misrepresented this is more akin to fake news than the article is, and likely to get your comment flagged/heavily downvoted.
> an article that has yet to be updated should be called "now inaccurate", not "fake news".
I disagree. It's a lie by omission, as same-day corrections on articles are a journalistic norm. By not doing so here, it conveniently furthers the Anti-Elon agenda that the tech media, including Techcrunch, has been confirmed to be pushing. Means, motive, opportunity.
There is a huge ethics problem with "journalists" in the USA, and they need to be not treated with kid gloves here (such as your lukewarm "now inaccurate" language). But what do I know?
Radio stations & TV stations use public airwaves and actually (used to, not sure now) had to prove they were acting in the public interest to keep their licenses. Doing public announcements were one way they handled that function.
You were able to access those news for free. Without any account. Once you had a radio or a tv, it was free and accessible for everyone.
Not the same for Facebook or Twitter. Even if technically free, you can be banned, or have your account deactivated because you didn’t give away your phone number as “security measure”.
> It’s always been that way. Before Twitter, it was private radio stations, private TV stations or private newspapers.
You can listen to TV and radio stations for free without an account or subscription and they can't cancel you (unlike FB/Twitter/etc).
Newspapers tecnically you had to buy, but reading the headlines at the newstand was free and you could always go to the library of coffee shop to read the whole thing for free.
I mean... for decades, the public institutions instead relied on private TV networks to do all of their communications. And propaganda. And they still do.
How is Twitter any different than FOX News or CNN?
They absolutely were/are private, even if they used a publicly owned medium to distribute their content. Other than an hour of public-service airtime on Sunday mornings, and lax FCC enforcement of a decency standard, those private TV networks can do/say anything they want.
You wouldn't put quotes around that word for cell-phone companies using licensed bandwidth, or airlines using public airspace, would you?
The broadcast companies are subject to FCC requirements that they must broadcast government emergency notifications. They do NOT have the power to shut down access the way twitter just did.
And they are not private. The public is legally entitled to receive anything broadcast over the radio spectrum. And as I and another poster have already pointed out, there are government licensing and carriage requirements involved with TV and radio broadcasters.
I keep hoping that in the near future we will think of companies/NGOs/influencers/Governmental Institution on twitter as using aol.com for their email.
I've viewed twitter wayyyyy less (only when someone links something) since Tweetbot stopped working and I think it's been good for my mental health. A login wall will take that usage down to zero, so good news overall.
I find Twitter really annoying to use now, since they made it so all of the replies from blue checkmark accounts get boosted to the top of the feed. I have to scroll past all of them just to find "normal" comments. The BlueBlocker browser extension is helping, but it can only block 1 account approximately every 15 seconds, or it triggers a rate limit and I have to sign-in to Twitter again.
You forgot to notice that Twitter has a pure chronological timeline now without any algorithmic recommendations. Surely that will outweigh people with blue checkmarks in the replies.
Same here. I haven’t really missed it at all (by contrast, I stopped using Reddit when the blackout started earlier this month, and that feels like more of a loss).
Weirdly, Twitter had started becoming so unreliable for me for several months prior (frequently not loading, video rarely working) that my click-through rate on Twitter links was already diminishing. But looks like it’s 0% from here on out.
Yes and it’s weird how weaning yourself off these things can go more easily than expected if you’re ”forced” to (because how you need to use the service changes too much for your tastes).
I think it speaks a lot about the _illusion of value_ these networks provide vs actual value.
As soon as I saw tweetdeck, which was like the gluttonous way of consuming all of Twitter all at once, I started thinking about the architect, from the movie The matrix. The guy with the enormous wall of televisions all watching neo in all of his different dimensions, checking to make sure he wasn't about to upset the balance of the matrix.
We are are not that sophisticated of animals. I mean we're not as dumb as dinosaurs were where they forgot about prey if the prey turned the corner out of their sight, but we're not as smart as we want to believe we are. So I think Twitter is Entertainment and
Should not be relied upon.
Remember when Twitter used to give archives of tweets to the Library of Congress? And had a firehose for folks to consume as many tweets as they could?
It's a shame that he's not able to escape his pathological belief that his product approach is the right approach, regardless of the grotesque impact he's making on what was a good thing for all of us.
Ironically, my initial reaction was “Oh crap. Public saftey orgs use this to broadcast alerts.”
My second reaction was “I wonder how hard it would be to take a list of twitter handles and scrape their feeds into an S3 bucket that’s fronted with a CDN.”
It went from $0/mo (as it had been for a long time) to $5000/mo overnight with no middle ground (for access to streaming data, no matter how small the volume).
Like anyone believes for a second anything that comes out of this guy's mouth. Even if true, who cares Elon? You're so good at shooting yourself in the foot, you might consider being a professional Russian Roulette player.
Haven’t we been predicting twitter’s degradation for some time? When Musk removed half of his employees many of us realised systems would remain running for some time, but at a certain point they would start degrading without intervention.
The more Musk makes changes, the faster it degrades.
How much time is it that the systems will remain running? Because it's been 9 months now and Twitter is still running fine. Time to admit that theory has been disproven.
I wonder what percentage of legitimate traffic is blocked by this. I would imagine that the majority of users don't have an account, by a large margin, correct?
I would not assume that, no. Following accounts is fundamental to using Twitter; I absolutely think the majority of people using Twitter are logged-in.
There are tons of usages of Twitter which don't need an account. All those Twitter links on this site for isntance. Some of them provide interesting input, however the urge to participate in those threads is low, as the need to follow those authors. The browser I use for HN is not signed in to twitter. Neither is my phone, where I sometimes get Twitter links in messages from friends.
Maybe to using Twitter on a sustained basis, sure. However I imagine there’s a decent-if-not-majority chunk that accesses tweets via Google/friends/news articles/etc
I ha[d] a bookmark folder with about a dozen twitstreams — no login/acct. I'm not signing up. Too bad nitter is broken, as well.
With all the public officials on Twitter (and FaceBook) publishing "public-facing" information, I'm surprised both are allowed to be/remain walled gardens.
To do my business taxes this year I had to DEMAND paper form acceptance, which was begrudgingly accepted once I went, in person, to the tax authorities [they want you to provide all sorts of tracking JUST TO FILE STATE TAXES, under the auspices of "two factor authentication"].
As a technosophisticate that intentionally avoids email and doesn't carry a cellphone... I weep for what my public-interfacing world will yet become.
Tons of people I share news with don't have Twitter - now I just wont bother, and I'm assuming it's the same for many others who used Twitter as some sort of middle man for that.
Unless someone was pulling in everything to build a new AI dataset or something like that then I'm filing this in the "bots bots bots" stuff from the takeover - a real problem that is completely blown out of proportion.
Easy solution: Regularly upload dumps of public tweets to the internet archive, like how stackoverflow used to do. Twitter's value is in live engagement, not in stale tweets.
I'd like to know how relevant search engine traffic is for Twitter. I was always under the impression that embed tweets and link shares would be way more important than search.
They’ve done fine with these employees for the last while. Trimming the fat is healthy, especially when Twitter has historically over-hired hard for no reason other than “growth for growth’s sake”.
There’s lots of legitimate reasons to criticize, but making a more efficient company and firing valueless employees is not one of them.
What makes you think all of those employees were useful? An employee does not have inherent value. It’s not as though Twitter never had problems before the acquisition.
"Several hundred organizations (maybe more) were scraping Twitter data extremely aggressively, to the point where it was affecting the real user experience.
What should we do to stop that? I’m open to ideas."
2. The scraping orgs dgaf & mask their IPs through proxy servers or through orgs that appear legit. For example, a recent massive scraping operation originating from Oracle IP addresses was just using their servers as a laundromat.
3. We absolutely will take legal action against those who stole our data & look forward seeing them in court, which is (optimistically) 2 to 3 years from now."
> 3. We absolutely will take legal action against those who stole our data…
What does “our” refer to here? Does Twitter (i.e. musk) own the data in any sense? Or does he mean it as “we the people’s data”?
Very off-putting to read that sentence. Obviously he’s trying to monetize the user generated data in this LLM rush as other avenues to monetizations have flopped.
This also really sounds like he's trying to pretend his data is some kind of rare commodity, when the reality is that it's bottom of the barrel trash as far as text data for LLMs goes.
Unless I misunderstood, he might actually have a case.
> In a second ruling in April 2022 the Ninth Circuit affirmed its decision.[5][6] In a November 2022 ruling the Ninth Circuit ruled that hiQ had breached LinkedIn's User Agreement and a settlement agreement was reached between the two parties. [7]
Yes, it was definitely the "data pillaging" that was degrading service, and not the fact that Twitter is now hosted on a Mac Mini under somebody's desk...
"Please respond to the strongest plausible interpretation of what someone says, not a weaker one that's easier to criticize. Assume good faith."
I'm not saying you owe CEO billionaires or billionaire CEOs better, but you owe this community better if you're posting here. If you'd please review and follow the site guidelines, we'd appreciate it: https://news.ycombinator.com/newsguidelines.html.
I'm a little surprised at this response, dang. I could understand if I was being hostile to the poster, but my sarcasm was directed at Musk (who they're quoting), whose comment about data pillaging I find highly dubious.
As far as snark, I see several other examples of that—also intended for Musk—in this thread. They don't strike me as either offensive or particularly constructive, so it's not clear to me why my comment was called out here. (Especially considering that there are a few other comments that definitely go beyond the acceptable levels of user-to-user snark as I understand them.)
I can avoid sarcastic comments about billionaires in the future, if that's a problem. If the issue was snark directed at another user, that wasn't my intention.
I'll also say that the "snark" rule you cited, while well-intentioned, seems very broad and selectively applied here.
It does not say “don’t be snarky unless scarasm is directed at a billionaire because then it’s ok because they have a lot of money and power, so we will allow it”.
You would then need to define some amount of money that would put someone in then “can be flamed” category.
The rule is not applied selectively here; it is applied to everyone, Musk included.
I mean—your response just now was snarky also. I don't think you were responding to the strongest plausible interpretation of what I said, either.
I'd say what's not clear to me is what to avoid in the future. I'm not trying to be difficult here—and dang is one guy dealing with the internet version of a city, to be sure—but I see sarcasm all the time on HN. The really toxic, demeaning stuff, sure, that has to go. In this case, it never even crossed my mind that what I said would be interpreted as targeting the person I was replying to. (While I wouldn't have flagged it, your snarky response, by contrast, was pretty clearly targeting me.)
Looking over the thread—and HN in general—there are no end of snarky posts, including yours, and especially in regards to wealthy tech guys like Musk. The vast majority of them are permitted. That's what I mean by "selectively." Going by your interpretation, no snark would be welcome at all; if that isn't the case, which I didn't have the impression it was, then what was it about my post that warranted a response more than the others?
Genuine question. I can observe consistent rules, but I'm not seeing consistent application of this one.
Moderation is dominated by randomness - we don't come close to seeing all the comments on HN or even all the comments in any large thread. That's 90% of the answer to "why did my comment get moderated and not those other ones". (https://hn.algolia.com/?dateRange=all&page=0&prefix=false&qu...)
The reason I saw your comment rather than the other ones is that it was heavily upvoted and right near the top of the page—and that's just the problem: snarky, shallow comments attract upvotes, which causes them to occupy prime real estate, crowding out better discussion, and that distorts the character of the thread and ultimately of the site itself. This is one of the biggest problems HN faces, if not the biggest.
You can say that this problem is caused more by upvotes than by comments, and I agree - but we can't address the problem at the upvote level (at least not publicly), and anyway if the flypaper weren't hung in the first place, the flies wouldn't have thronged to it.
It's impossible not to "selectively apply" the rules, the same way that not every speeder gets a speeding ticket, and of course when you've seen other people speeding worse than you (which they invariably do), it feels unfair that you're the one who gets the ticket. The main things to realize are (1) it's nothing personal; (2) the randomness evens out in the long run; and (3) the only way to keep HN going in a good way is for enough commenters to understand this and take up the work of following the site guidelines (or really, the intended spirit of the site) even when they see others not doing it. I hope this helps explain things a bit...
Paul Graham famously started to use Mastodon (but has not written anything there since last year). But the HN Status emergency “is HN down” channel is still only on Twitter. It used to be publicly readable at <https://twitter.com/HNStatus>. But now, if HN was to go down, only logged-in Twitter users would be able to see why.
If HN is down, I'll just try again in a few hours, or maybe tomorrow. Maybe I'd start getting interested about what happened it was down for a week or so.
Would HN being down count as an emergency for anybody else?
“Emergency” is used here in the sense of “sudden or unexpected occurence”, i.e. “fallback”. Maybe “backup channel” would have been a more appropriate term.
so is Musk. even if he weren't addicted to the platform, per se, he is to the exalted admiration and social proof. once one has acquired all the money in the world, what do they want? power
*raises hand* I've also avoided Twitter entirely, except where someone was linking into it from outside.
In the beginning I felt the original length-limit fundamentally doomed it to a certain kind of not-so-valuable conversation. I mean, hell, even this quick comment here is already ~381 chars. I know the limits have been raised, but I think its effect on the culture remained.
Never had a Twitter account. Never saw the appeal. Mostly annoyed when occasionally asked to read long-form writing split into multiple tweets. Now I never have to worry about that again!
https://nitter.cz/, from the Czech collective NoLogz, has a statement in place of the error message:
|
|
"Nitter.cz is not working, just like all other Nitter instances. The reason is Twitter blocking all access to it's content without login.
We are sorry, but there is nothing we can do about it right now and we are not sure if the situation will change in the future.
Don't trust corporations, especially those where one egomaniac has all the power. Use open-source and community driven solutions if you can (like Mastodon).
Sincerely, NoLog.cz collective
PS: You can also donate to us to keep our other services running"
Anybody feel like this is ironically going to accelerate the decline of twitter?
I'm never, EVER making a twitter account. However publishers still communicate with me via tweets I could see. Now that I need an account to view tweets, publishers just have a smaller audience.
All sorts of services seem to think that mandatory accounts drive "engagement". No doubt it works on certain metrics. Long term... we'll see. I know I still don't have a Pinterest account.
He needs revenue right now, and the other monetization efforts haven't panned out (blue checks, advertising, etc.). So he's trying to make a quick buck from user-generated data now that the LLM rush is at an all time high. For that he needs to limit access to the data in the first place, otherwise nobody would be paying for publicly available data.
This is how death spirals work. Twitter was treading water a year ago. Taking on lots of debt caused mass layoffs, worrying people about site stability and making them investigate other platforms. A lot of bad tweets scared away advertisers, causing more layoffs and desperation. Signed-in users engage more, so make all users signed-in users (no logical fallacies here).
Incidentally, has there ever been a leveraged buyout that wasn’t a disaster? Presumably there must be some which are a success at least for the buyer, or people wouldn’t keep doing it, but it really doesn’t seem to have a great track record for anyone involved, as a strategy.
"As part of the deal, Twitter will add about $13 billion of debt. Analysts estimate, based on terms previously laid out in documents related to the transaction, that Twitter would be on the hook for annual interest payments of more than $1 billion, compared with some $51 million in 2021."
> Why is Twitter forced to hold the debt for being purchased and not Elon?
Just because that's what was written into the contract when the acquisition happened. Something different could have been put in the contract, but this is what was actually written in it and signed off on by all the parties to the deal.
Saying he was "forced to overpay" isn't a fair characterization. As a joke that went too far, he voluntarily offered to overpay at what in hindsight was the peak, then signed a contract making it official. He was only forced to uphold the contract.
Twitter is full of low-quality garbage, partly due to the culture and partly due to the format. I am very doubtful that it has much value for LLM pretraining OR fine-tuning.
That’s a good point. I think (in jest) the data is invaluable for training automated trolls, for which various state actors should be willing to pay good money.
But more seriously, maybe the value is in it being a real-time source of new data, albeit the signal is drowned in noise like a needle in a hay stack.
Twitter is still $20B away from being in the green from even the most generous estimates. (Elon himself)
Currently Twitter is in the red, and he needs it to not be that and to generate a multi-billion surplus to pay back the investors he took up to finance this.
> Twitter is still $20B away from being (profitable)
Can you explain how Twitter manages to spend $20B per year?
Say they have 1000 employees @ $200k/year, that's $200m/year (1/5th of 1B). Where are the remaining $19.8B being spent? That figure doesn't pass the sniff test.
That’s because you’ve misunderstood. Twitter is worth $20B. We don’t know what they spend nor how much they make as a profit because they’re a private company.
What I’m saying is for Elon to even break even on the deal, using the information we have access to, he needs its evaluations to reach at least $40B. Once it reaches that, it actually proves itself as having been at minimum a neutral purchase. Albeit the real numbers it has to reach and how much profit it needs are both currently unknown.
Correlation does not equal causation. Although unprofitable companies might be inclined layoff employees, it's not implied that layoffs are a sign of unprofitability (in fact, the opposite could be true: laying off employees whose marginal value is low could cause a company to be more profitable).
Taking into consideration how much Spez thinks of himself as a Musk, we should be expecting Reddit to implement the same feature soon. We are just sitting by the sideline watching as the internet we all loved slowly dies in the hands of greedy corporations.
The discovery hurdle was part of the charm for me. I liked the era of small, niche communities where you knew everyone and developed real relationships with people that you never met in person. Discoverability is what leads to Eternal Septembers.
Especially since the best search engines are nearly useless for finding new old-style content… search is broken, the big platforms are broken, and random links from users of HN are now the only way I have to find new stuff. The cool thing is that most of what is posted to HN is relevant to my interests…
As pointed by countless people before me -- the hard part is not necessarily the hosting itself (which is still hard and could be a problem at a certain point), but to moderate -- to filter out spams, insults and illegal stuff etc. That is a time black hole. You have to admit that reddit does a much better job at fending off spams than an average forum.
What is the easiest and cheapest way for me to host my own forum online and invite people I know to talk? Consider I know very little about hosting, web dev, php, etc. I'm actually interested in doing this! Thanks.
Definitely join a Fediverse (e.g. Lemmy, Mastodon)! You can host an instance, but still "linked" to other instances and communities so you won't feel isolated.
I got flagged by dang the other day for calling spez some kind of insult. It bothered me.
Spez is inarguably incompetent as a leader and I realize that if I saw him in public, I would point and laugh.
Truly. I understand the fear of social media companies dealing with data scraping for rivals to run AI models, but it has been truly fumbled from a messaging perspective.
Reddit is useful in Google search results though whereas Twitter and Instagram are not.
For instance if you search "movies like X", on Google by default most results are automated aggregators or one critics perspective. If you search "movies like X reddit" you get more recommendations.
Reddit arbitrarily flags things as "available in the app" or "18+ content" to force you to sign in. They've been doing this crap since long before Twitter got loaded with debt by Musk.
I'm not sure it's as simple as a "greedy corporation" thing, because they've been "greedy" for a while. In a sense, they're even legally obligated to be "greedy". And the more we skirt the details of what (who) exactly causes these issues, the more we'll fail to understand such issues.
Not really. Blue Sky is the most promising replacement I've seen, but it's just another for profit company, so it will follow the same pattern eventually. I think an official government Mastodon or similar would work, but it really needs to be something hosted by a competent IT dept (meaning federal, in the US), with strict and well considered policies (who gets an account on it?) and with massive buy-in at all levels of government. So... no. Not really.
Twitter had a brilliant brand (which is now tainted). Chirping birds, positive visual. BlueSky shortens to BS and mastodon is an extinct animal. Lemmy, on the other hand, is kinda cool.
fwiw, Bluesky is fully federated (well, will be, it's in development, but it's well on the way, they just launched the federation sandbox the other day), and identities are portable, so it shouldn't be susceptible to the same dynamics as twitter. Plus, the dev team has stated a number of times that "the company is a potential future adversary" is one of the principles they keep in mind when designing the protocol. Plus, it's a Public Benefit LLC, for however much that's worth. And I really do trust the good intentions of the current devs and leadership (mostly the same people), based on my somewhat extensive interactions with them—I think their hearts are in the right place.
So of course it definitely could go badly fo a variety of reasons—but I think there's good reason to be optimistic that it will go well.
The issue I see is that the Tech Community, that form and influence opinions, is going to be cautious about investing time in another private social media company.
Mastodon has the mind share already as the de facto Twitter replacement.
Bluesky looks suspiciously like it’s dead in the water.
> Mastodon has the mind share already as the de facto Twitter replacement.
It did, until it got infested with far-left refugees who started banning entire instances whose users their have political disagreements with. Between that and the lack of ease of signing up or setting up your own instance, Mastodon is not taking over from Twitter anytime soon, although it has formed its own community that I'm sure will continue to use it. If Mastodon becomes even as popular as Tumblr now, let alone at its peak, I would consider that a surprising success.
As for the "tech community", some hackers did go over to Mastodon. That's great, but they didn't cause IRC or mailing lists to take over the world back in the day, and Mastodon is even more technically dysfunctional than those (making it so easy to completely block instances is a major issue). Call me when VCs start moving en masse to Mastodon.
On the VC moving to Mastodon bit: I guess that’s a very SV centric perspective?
I live in an obscure part of Australia, and the less VC posts I see the better. If I saw a post from @jason I’d know it was time to leave ;-)
But seriously, for me, I have zero interest in any of those VC posts or commentary. The value is in more local individuals and other interest groups being active. YMMV :-)
It baffles me that governments ever relied on an unprofitable ad-supported company to provide critical communications, especially where alternatives exist (email, putting notice on a website.)
And if it’s life or death, there’s Emergency Alert System. Goes on TV, radio, and straight to your phone, complete with the Cold War-era alert tone. I hope Twitter merely supplemented that?
texts through registration on the site of the city hall, if cell braodcast isnt implemented by the phone company
public emergency sirens
radio
TV
actual website of the city hall
local newspaper
social fabric, with residents actually calling each others, for non emergency topics ?
(Hacker news ?)
Twitter has never been a great solution on its own. It could have contributed along with other channels of communication, so you should already have these.
If the local authorities have an actual life-and-death emergency broadcast to make to the entire area they serve, I suspect they have a more effective means to do this than Twitter. As a matter of public safety, they need to be able to inform everyone, whether they've subscribed or not, and in a way that does not require users to think to check for a notification, or even to have a special device (like a cellphone to receive push notifications). Those extra mechanisms are great and helpful, but they don't replace a true public emergency notification mechanism.
Where I live, the tornado siren, which is beyond extremely loud and mounted high up on a pole in the highest point in the neighborhood, can be used to broadcast PSAs. It screams "THIS IS ONLY A TEST" at noon on the first Wednesday of every month. And you hear it whether you want to or not.
> If the local authorities have an actual life-and-death emergency broadcast to make to the entire area they serve, I suspect they have a more effective means to do this than Twitter.
Youre not wrong, but that doesn't mean they make effective use of them. During one of Canada's deadliest mass shootings, the police elected to only post information on Twitter.
For them? Either be a part of a wider alerting system, or an app. Actual emergencies - push text messages to the area, FM/AM radio.
The second they should already know about / be a part of. Maybe email them to check?
For the first, it really depends what area you're in. Australia/Victoria for example has a state-wide https://www.emergency.vic.gov.au/respond/ which has its own app with location/severity based alerting. There may be something similar around you.
I check my local news station's website every day for good local news. It always has a big banner if there's relevant news like a weather warning, big road closure, fire, etc. The website is pure garbage and viewing it with an ad blocker is mandatory, but it at least loads without all the dark patterns like Twitter.
My house was in the evacuation zone for most of the recent fires. I just kept this link open on my phone and refreshed it as needed.
Quite often they will tell you when to expect the next update, ie) within an hour
Even if I had a Twitter, I’d say the random notifications would be more frustrating than valueable in an emergency situation. If I’m in a safe enough spot to look for updates online I can pull up the local OEM Twitter.
RSS. It’s quite good for an application like this where the publisher has the resources to operate a website, and it allows multiple different consumer applications to all view the published text.
I remember the olden days when something like this would be voted to the top. A useful solution to a posted problem is what I hope to find for topics such as this.
At the end of each snippet is a t.co link with a /{tweet id} at the end. You'll have to click on it and copy the status/tweet id from the url after the "%2Fstatus%" part. Paste that number into an embed link:
https://platform.twitter.com/embed/Tweet.html?id=16763153424...
correct. the first link you can use manually. The second link is a browser addon. The 3rd link you save to your computer then "import" in that addon to always rewrite twitter.com/username to the first link.
I was just going to say - lots of media companies routinely embed tweets, breaking that would be disastrous PR. Twitter is currently kept alive by media people; if they switch, the platform will die very quickly.
I wonder if this is all a result of the API price hike. Folks probably tried to keep integrations alive by scraping, so now there is a lot of extra traffic on the main site. If integrations start acting like embedded calls, they will have the same problem there soon.
And now imagine a citizen wants to quickly check news/updates/whatever from a government agency or a city council which doesn't have a fediverse account
Why the hell are government agencies using Twitter/Facebook for official communication in the first place?
At the very least if these sites are being used for official communication that might be critical to peoples safety some sort of privileged status or ToS should be negotiated. Can you imagine Musk banning some random non-USA government agency because he had a fit while high at 3 am?
> Why the hell are government agencies using Twitter/Facebook for official communication in the first place?
Exactly this. It's fine if they use twitter to syndicate news that is also announced on official government systems, but not as a primary and certainly not as a solitary distribution method.
> Can you imagine Musk banning some random non-USA government agency because he had a fit while high at 3 am?
That would be hilarious and maybe it would result in some people learning that twitter is in fact a private corporation that can do whatever it wants, but i doubt it - similar incidents proved that large swathes of users believe twitter is or should be treated as public infrastructure rather than prompting significant moves to user controlled platforms
This is one of the biggest scandals nobody is talking about.
Any talk about privacy awareness is invalidated when public sector entities endorse these platforms and encourage citizens to participate.
Any talk about the public sector not picking winners is a joke when they explicitly advertise and provide links on their websites to particular platforms.
We have normalized alot of abnormal stuff in the past decade...
How long did it take for expertsexchange to finally stop showing in Google results despite being super obnoxious? Yeah you could scroll way to the bottom, but that only worked if you came there direct from Google.
> Why the hell are government agencies using Twitter/Facebook for official communication in the first place?
It's the responsibility of the government to make information available where the citizens are. As the citizens moved from radio and TV to social media, the government followed.
It is right to be present on Twitter. But the question is: Should it be the single/primary channel or only secondary channel filled from a primary source, like their website?
Of course, running a website, which allows those quick edits requires with dealing with secure infrastructure, maybe apps dir field agents to write something etc. which they could all outsource to Twitter (and vendors of tools built around Twitter API for scheduled tweets etc.)
Its somewhat similar with public broadcasters (BBC, German ARD etc ) putting their content on YouTube (where consumers are) vs their sites (where they control it, including privacy concerns)
Definitely this. The big thing now will be: where is everyone? Twitters active user numbers are fine, but for how long? Likewise with Facebook as younger people aren’t showing up there. Will the governments of the USA need to be on every single platform? Should USDS just make a new news site just for the governments to broadcast on?
I've definitely seen critical info communicated either only on Twitter, or first on Twitter and only much later elsewhere. Not sure if it was alerts ("chemical plant on fire, close windows") or crisis communication ("emergency water supplies being distributed at Foo street"), but it was a case of "use Twitter or suffer serious consequences".
Stuff like "public transit line 17 out of service" being announced only on Twitter is completely par for the course.
I like to be able to point to times when Musk errs from his stated free speech mission so I'm curious for the journalists in question. I know he upheld the Alex Jones ban explicitly because he found Jones' speech distasteful. It'd be nice to have a more sympathetic person to refer to.
> Can you imagine Musk banning some random non-USA government agency because he had a fit while high at 3 am?
Not only, but also.
Does the Chinese government run an account? Have American politicians been as upset about this as they seem to have been about TikTok? I'd check the former, but, well, the subject under discussion.
Simple, if you are not there you do not exist. Go and check how many of your contacts follow the oficial accounts of your local government.
Also, the common layman isn't anyone that suddenly gets the urge to check your official webpage, if you are lucky you are in their social media results.
Looks like this is the best moment to move to the fediverse. Each country to have its own instances and accounts for all public institutions and governors.
Relying on Twitter for that was a lazy mistake to begin with. Why would a government agency rely on a private, unpaid third party, without any contract, for anything of consequence?
I just ran into this problem -- not being able to view tweets without logging in. As much as I hate Musk, this is clearly the trajectory of all platforms. Without a unified push towards self-hosting or the fediverse, the internet as we know it is over :(
I like how we keep pretending that any of this complicated shit is better than good old phpBB. There are no modern inventions for social interactions which made actual interactions better. They're all incomprehensible UX nightmares used mostly by the loud minority of users on the web (i.e. Twitter actively engages with only 7% of the entire internet user base) who censor each other and then fight over how to make it all "better" by over-engineering everything.
I don’t want to make a million accounts for a million separate forums. I want one account that I can take with me to every forum.
Both of these issues were solved by Reddit. This was its major value-add. The user base brought all of the remaining value with them.
This is also the value of the fediverse, of which lemmy is a fine example. Yes, the technology is way more complicated than phpBB, but it solves these very challenging problems which present huge barriers to growing an individual forum (which must be overcome once again, every time for every forum).
I'm not really convinced that discovery was a problem with the old forums. There was no insatiable need to know where everything under the sun lives. You'd typically just follow a few forums around your interests. I think it became a glaring disadvantage when Reddit introduced an overabundance of options and allowed everyone to subscribe to 20 things because they could, not because they needed or wanted to. I think Reddit's value-add was community moderation without self-hosting.
This is akin to online dating. Nobody needed 5 dates a week 20 years ago and because it's an option now doesn't mean it was a problem than. Optionality is just a byproduct of social platforms.
I'm not really convinced that discovery was a problem with the old forums
If you're referring to the time when the "old forums" were new, that is a world which no longer exists: a world where Google search results were useful and not overloaded with paywalled sites and SEO spam. Today, you're going to have a very difficult time finding those "old forums" unless you know the exact name of what you're looking for. And forget about browsing.
As for "people today have too many options, back in the day we had fewer options and we were fine!" that's a very old argument you'll have a hard time convincing many people of.
> I want one account that I can take with me to every forum.
Why do you want that? Why would you want your identity on a functional programming forum to be the same as on a Star Trek fans site and a furries meetup group?
That's an easy problem to solve - you can have 3 accounts
The other alternative where you don't care if functional programming and Rust programming forums are on the same id is the issue without the option of a single account
Yep. Until there’s a big fat “Create Account” button, users are going to remain confused about instances. We’ve tried explaining it to them for years and they still don’t get it. The abstraction is clearly just a bad one, and needs to be swept under a rug somehow.
Been over for a long time. We've had a lot of consolidation into Reddit (which, you can browse mostly anonymously, it will just beg you to death to log in unless you use the old site); and we've also had a mountain of consolidation into Discord (the most unsearchable system ever designed).
People stopped hosting their own forums. Frankly, it's hard to not see why. The constant spam and people avoiding bans wasn't helpful - and modern forum software like Discourse is pure agony to set up and maintain if you don't know what you are doing. Not that forum software hasn't always been hard to set up, but the modern software stacks are particularly hard to manage. Also, what normal people see as good UX, in my experience, almost completely does not match what computer engineers and the average open-source contributor sees as good UX.
> modern forum software like Discourse is pure agony to set up and maintain if you don't know what you are doing
I'd like to know more about why Discourse is this way. Why the fark can't I just docker compose it up and running? I'm almost but not quite thinking about paying for a hosted Discourse solution since time is money. But why do they make it so hard?
Is anyone saying they're obligated to support the old site? I don't think that's a supportable inference to draw from people's observations that the new design is hot garbage.
Disagree. I'd frame it as the "popular web" as we know it is over. There's plenty of other space on the internet for other web experiences that are different from what corporations have given us over the past two decades.
I don't know how anyone can respect a man who calls a professional rescue working trying to save kids from a cave flood a pedophile. Musk has always been a piece of shit.
Hopefully this marks the end of posting direct tweet links to HN.
I’ve been avoiding clicking Twitter links, and it’s frustrating to see them on the HN front page but then having to infer the content from comments.
Maybe HN could even have a “Submit a microblog link” feature for that kind of content?
When submitting a microblog link, there would be a small text box where you could copy the content of the tweet/whatever. This should be fair use as a quotation (but IANAL). It could be an important archival feature for situations like the current one, where all past HN submissions that point to Twitter are suddenly behind a login wall.
You realize you don't have to click on every link, right? If someone publishes something on Twitter/Tumblr/Facebook and you don't like the form on that particular website, you can just ignore it and move on.
There are never Facebook or Tumblr links on the HN front page. Twitter seems to be the only proprietary social media that has enjoyed enough hacker cred to get upvotes.
I still have a few accounts I glance at from time to time. Hockey, Game Devs, Artists, etc. who haven't migrated away despite everything, so this is kinda obnoxious.
I created some Redirector (https://einaregilsson.com/redirector/) rules to redirect Tweet and Twitter Profile URLs to their HTML embed equivalents.
Should be able to just import the rules and it seems to work alright with some caveats.
* I have no idea if this will continue to function.
* I've only tested some random links from my Discord and Slack groups.
* Profile links only show the most recent 20 tweets.
* Tweets will show quote-tweets, but no replies (though maybe that's a good thing).
* Obviously won't work for mobile.
It's a very myopic decision on their part if true, even worse than the API pricing update. This will stop any form of viral content on twitter from reaching non-internet people. Forget about sharing that one twitter link to friends or relatives. Instead it will make the twitter echo chamber increasingly detached and irrelevant to the larger discussion. On the long run, this decision changes the narrative of twitter from being a catalyst of political change (e.g. Arab Spring) to a tumblr clone with ecelebs. I don't have an account and never will. I followed a handful of accounts via nitter rss. Now I'll just wait until they build their presence outside the platform.
Different contexts call for different approaches. "Write once, publish everywhere" is ideal for read-only content. For a social network that is user-centric/identity-focused (like Twitter), federation makes sense; for a social network that is "topic-centric" (like Reddit) you can just have individual forums like the old days.
I find it tedious to update various social media platforms by hand, especially when each platform has its own rules and conventions. There are paid services that help but they often don't cover all of the platforms that I use, or are prohibitively expensive. Also if you just post a link to your site some social media platforms will treat you as a spammer.
Twitter has now endured Instagram levels of enshittification. It has been a crappy product since the mid 2010s, but at least it was minimally usable back then.
A few weeks ago, we intentionally slowed our invite roll-out while we built more moderation tooling and capacity for users on the app. We staffed a content moderation team with shifts that cover a 24/7 schedule, and consulted with trust and safety experts to establish new processes and policies to support a growing userbase. We’ve resumed sending out daily invites to the waitlist, which is where the majority of users already on Bluesky received their invites. For those who don’t know someone personally with an invite code, the waitlist is the fastest way to receive a code, though please be patient as we work through the list.
"
Because they remaining main usage of twitter seem to be people "tweeting" small important (from their POV) bits of news. This could be political news but also e.g. announcements of content creators.
The changes in the algorithm already where not so grate for some people for this use case.
But most important for this use case is that this tweets need to be world readable even if not world discoverable.
With this gone a lot of people now have to look for a place where they can do world visible announcements, and at that point why not only use that place? Especially if it doesn't require you to e.g. buy something like twitter blue to increase the chance that people subscribed to you see your announcement.
I’m using twitter as much as ever, the live content is just too good to pass up, I set up Lists and use it to read only the category I want and you don’t need to follow them. You don’t have to like Elon but the stuff people write(given the right profiles), the concentration of it, isn’t really offered anywhere else.
Hopefully this will drive businesses off the platform and Twitter will become a thing of the past causing billions being lost by Musk and anyone else who think his idiocy was good for the platform.
If you need to create an account you just won't bother. I find myself caring less about twitter now, when you could view tweets it would get you motivated to get involved, not that you won't be able to I can see a lot of traffic just drift away.
Yeah, I occasionally follow twitter links to things, but I'm not going to make an account just to see tweets. All this does is make sure I never use it again.
It's funny that creating a twitter clone has been a "hello world" kind of project for most web frameworks over the last 10 years but here we are without any feature-complete alternatives.
It doesn't have to do with feature completeness but rather the network effect. Even if you build a pixel-by-pixel copy of Twitter how are you going to convince everyone to move there?
Yes, I was going back to Twitter for some days to follow updates on the Prigozhin road trip last week. But the quality of the news had noticeably deteriorated compared to the past, as Twitter's algorithm now promotes blue checks above everything else, so you now get updates from such notable experts on the Ukraine (as well as, I bet, many other topics) as David Sacks, Mario Nawfal, and Kim Dotcom.
Most of the news, images, and video originates from Telegram. Even if you don't want an account you can view channels without logging in... For example: https://t.me/s/pilotblog, but there are usually t.me watermarks on videos so you can find plenty of others.
As someone who’s been consuming a lot on Twitter and Reddit, can you recommend a decent set of telegram channels that I could follow to stay up to date?
Not really, since I try to not follow it too closely for my own sanity's sake. The channel I mentioned is Denys Davydov, a Ukrainian who also has his own Youtube channel where he posts updates.
If you want the most up to date stuff you would probably have to follow some Russian and Ukranian channels, Telegram has built in Google translate to make that slightly easier. Reddit is probably a good place to start to find some.
I follow Davydov on YouTube, but I tend to avoid most of the telegram channels that a lot of YouTube people suggest because they tend to use it as a place where they can share combat and violent footage that YouTube doesn't allow.
While I'm interested in following the war, I don't have a desire to watch combat footage so I've been a little hesitant to jump into his telegram channel.
I kinda get the sense that it's probably not super easy to find a telegram channel that doesn't post war footage.
Public Twitter lists seem like the sort of thing that's quite scrape-able though, even behind a login wall. With sufficient caching & semi-randomised access it should be fairly hard to detect which account is doing the scraping.
Most English-language content about the Ukranian war is slanted in favor of Ukraine. This is partially because of the relevant military alliances (Europe and the USA support Ukraine) but much more because Russians are the aggressor here. War isn't clean or simple, but there are clearly good and bad guys in this one. The Russian justifications for the war are 100% pretextual and invalid, just like they were in 2014.
I'm not sure why anyone wants "neutrality" to mean 50/50 airtime, instead of attempting to present the best available picture of the world, even if it's not favorable to one side.
No no, you don't understand, the war was started by Poland! They attacked Germany in the Gleiwitz incident, you have to get unbiased news from both sides to properly assess the situation and stay truly neutral and enlightened.
Looks like Twitter was officially evicted out of their Boulder office today. Had a fire sale on furniture out on the street, at least until the Sheriff seemed to stop employees from going into the building anymore.
What this needs is some way to randomly select tokens from a (self-hosted) token dispenser. The dispenser can be fed fresh tokens through token donation from all those who claimed to have left and/or are planning to leave Twitter, that should provide enough tokens for the forthcoming decade.
What if we just had sites and RSS-like aggregators? You could subscribe directly to the sources you like. You could then publish the aggregation. In turn you could subscribe to an aggregator, and perhaps even reaggregate their content, too. In this way we can have a distributed method of "following" content that we like.
Basically this vision is one where everyone run's Google Reader in their browser and, if you're really gung-ho, you republish via some VPS hosted thing. The structure is a little like DNS - a hierarchical database.
I'm thinking it'd be nice to make a DB mapping people's twitter ids to their preferred RSS feed in anticipation of this future. Just not sure how to deal with commenting/ feedback/interaction. Guess that's what the fediverse is for.
I’m not active on social media for the most part, and have to remind people not to send me links to sites that require a login (Pinterest for example). I don’t have a Twitter account, but there were accounts I liked to browse occasionally. In the months before the Musk takeover, Twitter kept coming up with new things that you couldn’t do without logging in. Finally, it was completely unusable. One of the earlier easy wins Musk made was undoing all of that. Now, on top of everything else he’s managed to spectacularly torpedo, we’re back to this.
Does this mean companies will finally stop putting their official announcements only on Twitter? I already deleted my Twitter account months ago and I'm not about to create a new one.
There are two basic strategies for publishing on the web. Either you lock up as much valuable data, forums, posts, and pictures you can, and provide a web based frontend to your service. This is the Minitel model, as exemplified by Facebook.
Or you try to ride the coattails of network effects and remove any obstacles to your information, index public data, and generally tries to weave in the service in the public web as tight as possible. This is the www model, as exemplified by Google.
Then there are the ones in between, such as newspapers, who generally wants to hide their information behind their service to increase the perceived value, but also wants to be reachable from the public web because without findability they have no value. This is of course paradoxical reasoning with no end of problems and no successful businesses.
Twitter from the start was part of the web 2.0 movement with a clear www strategy. Now they are doing a strategic shift. But how valuable is twitter when they're no longer indexed by services such as Google?
I can not see how they can grow their business in the long term from this. They lose the sentiment of a mirror of public discourse and instead will become like any web forum. So there will be zero journalistic value, and why would celebrities want to hang around then?
It's not even a slippery slope. It's just a slope.
The most recent updates are available on that page, but for anything older than that you'll need a Twitter account to read stripestatus on Twitter. Even their Atom feed is a useless river of "A status update was posted" titles with truncated tweet content and t.co links.
It's such a shame, Twitter used to be so useful for stuff like this.
The thing is if it weren't meant to be temporary I'd still expect him to undo it. Twitter is iconic, it's a big part of "the news" in a way. It just doesn't seem like it would be the same thing if it had exclusivity. So I'd expect them to reverse the decision after seeing the drop in engagement. Just like they did regarding the ban on promoting one's Mastodon account.
I have an archive of my tweets from a year ago. Not sure if the format changed, but this makes an html file with the full text and images and vids. Format to taste.
import datetime
import json
import os
import sys
out = sys.stdout
media = {}
for med in os.listdir("data/tweet_media"):
tid = med.split("-")[0]
exist = media.get(tid, [])
exist.append(med)
media[tid] = exist
out.write("<html><body>\n")
with open("data/tweet.js") as d:
vals = json.load(d)
for val in sorted(
vals,
key=lambda val: datetime.datetime.strptime(
val["tweet"]["created_at"], "%a %b %d %H:%M:%S %z %Y"
),
):
tweet = val["tweet"]
out.write("<div>\n")
out.write(f"<i>{tweet['created_at']}</i>\n")
for fname in media.get(tweet["id"], []):
if fname.endswith("mp4"):
out.write(
f'<video controls><source src="data/tweet_media/{fname}" type="video/mp4"></video>\n'
)
else:
out.write(f'<img src="data/tweet_media/{fname}"/>\n')
if "full_text" in tweet:
out.write(f'<p>{tweet["full_text"]}</p>\n')
out.write("</div>\n")
out.write("</body></html>\n")
So is it down just for me? Since for about an hour now site loading is aborted for more than 20 redirects. That is, not logged-in. – But, how do you log in, then?
Update: 2 hours later, still not loading with Safari/Desktop. (Is there any QA, at all?) FF works though and immediately goes to an otherwise blank page with a log-in dialog.
I'd like to know what happened to Quora. It's now full of Chat GPT answers and self-proclaimed experts who try to sell you their online course on gemstone energy driven entrepreneurship.
That is what happened. Place is a war zone, far cry from the beautiful thing it once was. A hardy few are still slugging away amidst a rising tide of crap. Unless one knows who is who, they are hard to find.
Same, but I've had this issue on desktop (Chromium and Firefox) for weeks now. I think it's some misapplied filtering rule or something, since before this recent account change I could still see Twitter on my mobile browser, without redirects.
The money printing and tech investing bonanza has allowed many programmers to flex their programming expertise without considering real-world resource costs. Now those bills come knocking and everyone acts like the previous utopian paradigm was somehow sustainable. I'm calling bullshit.
If the fediverse ever had this kind of scraping pressure, it would collapse in minutes.
It’s naive to say that this is the inevitable result of wider forces. If Elon had never offered to buy Twitter, or had managed to weasel out of it, you can bet the API would still be a thing and the login wall would be much as it was a year ago.
Twitter before the buyout was propped up by the forces I already mentioned. It was a resource black hole, and your claim that it was sustainable is, with high probability, categorically wrong.
They appear to have also drastically decreased the rate-limit for viewing tweets. I've hit 429 errors twice browsing my timeline normally, and looking at the headers shows the current rate-limit is 50 tweets per 15 minutes, at which point you get locked out.
edit: Scrolling a thread counts as a hit against this every time it needs to load more tweets, so this is very easy to hit.
Since Twitter the company also did this in 2021 (https://news.ycombinator.com/item?id=28289263), this is more an example of the Elon regime rerunning product experiments in production for themselves, and thus retreading ground unproductively as the debt service counter ticks away.
One outcome of no longer allowing unlimited public access to tweets is that it will become very difficult to cache or archive them.
(And Twitter won't want to allow caches or archives since if course they could be used to get around read rate limits)
To the extent that tweets (does Twitter not call them that anymore?) are an important part of the public record, including being able to verify whether someone really did tweet a certain thing at a certain time, this is a little bit scary.
And just generally for our ability to preserve historical record, already threatened by the digital world, and apparently getting worse instead of better.
Honest question, should services that host user generated content be obligated to provide that content "for free" through APIs or scrapers? On one hand, users created the content "for free" for the platform to use and monetize. On the other hand, providing the content through an API without any ad/monetization potential doesn't make good business sense.
Is there an acceptable threshold of free viewing before it becomes abusive? (Think, getting a single free See's candy from the store vs. employing an army of people to source thousands of pounds of chocolate treats.)
With the Reddit API issue I'm honestly unsure where I stand. I love(d) Apollo and want it to succeed, but Reddit is doing the work and not getting the rewards. Where do you draw the line at "fair"?
No because the user generating the content isn’t a virtue of any sort. They’re just doing free work for a company. If they choose to do that, that’s their choice.
In fact I think this is good. It makes it very clear that no, it’s not your content and no, you don’t deserve any rights just because you feel like you own it. Twitter will do as it pleases with “your” content.
I would very much welcome a far more informed environment where people were forced to face the details of IP rights and what it means to post content on these services.
You own the copyright to your own tweets. When you tweet you give Twitter a license to display the tweet, but you still own it. This is all spelled out in the Twitter terms of service.
Well I guess we’ll work out two things very quickly:
1. Is it worthwhile giving free labour to these services by generating their content,
and,
2. Do we want to login and/or pay to check user generated content?
Personally, I think the answer will be no. If these services generated their own content, which we actually value, then it would be a different matter. But they don’t, so if they put up road blocks I suspect they will get a bit of a shock to learn they aren’t actually as vital to society as they thought they were.
No one's obligated to do anything. All else being equal, people prefer convenience. If the service is less convenient, less people will choose to use it. If the content is freely available, it will be scraped.
On a related note: any ideas on why Bluesky seems to be taking so long to open to the public? They had a beta program a few months ago, and everyone seemed to love it, and now nothing?
Surely now is the time to capitalise on the discontent on Twitter, even if it means dealing with a few scaling pains.
Unpopular take: large platforms can do anything, any kind of evil moves towards their users and still mostly get away with it. We can see that it generally works with Twitter, Reddit, YouTube and lots of others.
I don't know for sure if it is possible to fight it. Centralized platforms will always win because they are very convenient and UX is very smooth while user plays ball by platform's rules. Migrating to decentralized is mostly for geeks.
I am geek myself, but I still can't find energy to migrate at leas email to my own domain. Instead I keep using GMail, despite all the risks (I am citizen of Russia, so in my case risk of deplatforming from Google is even higher).
This also seems like another attempt to combat web scraping.
They put search behind login and now tweets themselves to try to push people to use their API. Twitter is still the bigest source used in public sentiment analysis and it's still relatively easy to scrape with login so this just shifts everything to grey/dark markets. The essentially means public researchers, students w/e lost access while dark market value increases significantly.
So, as per character, this just empowers corporations and punishes public. Hopefully this means the upcoming end of Twitter.
(just for the statistics, I know it does not matter what is problem for me specifically and what not, just one point of view added. a person like me nervous about tracking my internet activity and blocks embedded twitter, does not like the twitter lifestyle of brief, single viewpoint, and oppinionated texts so never goes there by will, there will be no change. well written articles are much better anyway than brief and sudden reactions the twitter is made for, basicly smalltalk before the real conversation.)
Well this right here is the penultimate act in the death of Twitter. They've taken the principle place Twitter can monetize it's usage - users who don't have Twitter accounts but are linked to Twitter content - and removed the ability to show ads to them in favor of trying to get account sign ups.
The final act will be when they kill Twitter embeds on the basis of too many people are now viewing Tweets but not signing up for Twitter.
Literally doing the latter thing - killing embeds - would've been a more sensible decision.
Twitter is falling apart. Recently almost everyone I know got accused of being a spam account and told their accounts were locked. It’s not clear what this actually meant as they could still use it normally. Though I do know one who had to fight to get his back. I also am disallowed from liking tweets quite often and am told it looks “automated”. I also noticed a period on Thursday where they turned off the spam filter and I was inundated with likes from spam accounts
It is insane watching the tech elite continue to conjoin themselves into a shape that allows them the ability to actually say Twitter is going well with a straight face.
If this is Linda Yaccarino's first major policy decision as CEO then it's not looking good. I really don't know what they (corporate) can do at this point.
Imagine trying to do your job closing ad deals and the owner decides to block public access without prior notice. Nothing says "we're a trustworthy partner who won't damage your brand," like major changes made seemingly at random.
> Nothing says "we're a trustworthy partner who won't damage your brand," like major changes made seemingly at random.
This has been Twitter's Modus operandi from well before Musk acquired them.
They announced new features through Tweets (remember Fleets?) with glaring issues at launch (no authentication required to view a Fleet) and without any corresponding API documentation. The GraphQL that backs their website has more features and bug fixes than their paid API!
They also famously do not have a staging environment, which frequently caused issues when new features were deployed or tested with a subset of users.
Twitter has never been a trustworthy or reliable partner. They are just more of an obvious dumpster fire since the Musk acquisition.
Staging environments are really hard at scale and I don't think anyone's really cracked that nut yet. The coordination between umpteen teams means that if there even is a staging, the test data is not totally representative, the systems are wildly out of sync, and it's either too stable, or too unstable. So you deploy to staging, which doesn't really give any signal other than it doesn't (or maybe it does) crash the kernel, so you release to prod with a gradual rollout and just pray.
Twitter's got its share of issues, but not having staging isn't one of them because there's not much value for massive distributed systems like that to have a staging environment, not relative to the effort required, anyway.
And people said I was being a Luddite for saying "just copy the text or take a screenshot", that's a lot of "news" articles at this point.
Definitely disturbing that journalists (especially) figured it was good archival practice to rely on the Twitter API in providing context.
For years, if I didn't enable twitter's javascript, news articles are missing images and quotes, obviously so. It's embarrassing, I honestly don't know how they recover from this, I don't know why they kept relying on Twitter embedding when screenshots and copy/paste work better and don't break.
I grew up with the practice of never putting more of my life in the digital world than necessary. Given the recent Amazon smarthome snafu I don't see a reason to change.
Many public or semipublic institutions like local and federal government, police, public transport made regular announcements there and sometimes only there. Hopefully this practice will change now that they see that it can become non-public in an instant. Citizens shouldn‘t be required to subscribe to large, private, foreign media companies to see announcements of their own government.
As an amusing aside, you can search for "username twitter" for many of the people posting here on hn.algolia.com and get a sequence of "I don't use Twitter" then "This Twitter account is decent" in a short span of time which makes me suspect many of these claims are not true.
For my part, this is an annoyance since I use nitter's API to feed Tweets to a Slack I share with friends.
This is got to be reversed eventually because Twitter was a public square and now it is a closed square where every tweet is logged on who sees what.
Nearly everybody is going to be getting off of Twitter now. It no longer is what it used to be. A place where celebrities could brag about themselves publicly.
Remember, this is what influenced Facebook to open up and make all of the profiles public.
I wonder whether an alternative could be like a Reddit or mastodon with paid-for subreddits/servers (not familiar with mastodon) being able to be started like a colocation service ala linode. Ie customers just sign up and the backend provisions them infra as needed. That seems like a way to answer the “nobody wants to run their own server” problem.
I wonder if we'll just start seeing people sharing accounts, and growing the (currently mostly underground) ecosystem around that.
There will probably also be tons more abandoned accounts halfway through the registration process, as the last time I remember trying to register one, I was asked to provide a phone number and noped out immediately.
Somehow they required an account to view more than a few replies. Then it got „better“ and they removed that requirement. And a few days ago I realized I can’t view anything at all without logging in.
I‘m not really sad about that change. Just going to miss out some things because I don‘t see why I should register to read a few tweets a week.
What makes these hacks think I wouldn’t just take my ball and go home? Not sure they care, but I am in a juicy demographic, so the joke’s on them. Social media has a short shelf-life, as long as I can remember. To pull a stunt like this, well, it is ballsy to say the least. Farewell, Tweeter, you will not be missed!
I noticed this earlier today when trying to follow a quote from linked from a new York times article. I thought "well thats fucked up how will anyone know what they said" lol. Twitter is such a crap show now lol. Really only useful to people who use it.
A lot of local governments (public transit, police, fire department) use Twitter to provide service updates and even critical information when there's some kind of local emergency. I hope they're migrating off already but I kinda doubt it.
Musk should sue for DDoS if the TOS don't allow massive scraping. He should also sue to explore the general legality of the AI racket, because copyright was made for humans and everyone on Twitter has posted under that assumption.
I tend to spend way more time on Twitter than I should, so I blacklisted it on my router and only accessed it through Nitter. Since I will not remove it from the blacklist, that's it with Twitter. Overall this is probably a good thing for me.
Wow what a hit piece. The tone of the article is so overtly biased against Elon/Twitter, TC editorial team lose whatever little journalistic credibility they might have had.
> Musk — who is no longer CEO of Twitter, but still deeply involved in operations — may also be motivated by a desire to prevent AI tools from searching Twitter.
This seems very unlikely. If they really just wanted to stop just AI tools from searching twitter, it would be very easy to prevent them from doing it at scale by imposing basic rate limiting and device intelligence (or even something like the puzzle LinkedIn makes you solve before viewing someone's profile while not logged in).
I'm very confused as to why they may not want unlogged-in human lurkers who are still seeing and clicking on ads when on the Twitter website.
> This seems very unlikely. If they really just wanted to stop just AI tools
Same issue with Reddit, it's a false excuse for embarking on some other kind of cash-grab policy.
They claimed the almost-no-warning API changes were necessary to stop the "AI", except that all the big (and therefore significant) actors could have been stopped by a change to the terms of service or some modest rate-limits.
Guess I'll just be checking it less often then. I have a Twitter account but don't like to be logged in on my phone and potentially leaking location data.
There might be a couple sides to the story if one was to view from a less emotional perspective. People who genuinely enjoy reading the site, but value their privacy have a good argument because now they've been denied their rights. On the other hand, there's always been a serious problem with bots scraping the site, which drives up costs. Another consideration is that they're trying to make the company profitable and sign-ins is a measurable metric for advertising and possibly being able to weed out some bad actors. Whether that will work out the way they intend remains to be seen.
Is there a way to use embed links to stay abreast of a user though, as opposed to only individual tweets with predetermined urls? When you click on the embed it's just going to take you to the site to log in.
For the longest time, Google had an agreement with Twitter to get new posts in real time with a firehose feed. It was active at least in 2009–2011 and 2015, not sure about the current status.
https://variety.com/2015/digital/news/google-makes-peace-wit...
The overthinking, speculation, and wasted thoughts in the comments due to misinformed people attempting to spread unsubstantiated claims is quite shocking.
"Several hundred organizations (maybe more) were scraping Twitter data extremely aggressively, to the point where it was affecting the real user experience.
What should we do to stop that? I’m open to ideas.
5:06 PM · Jun 30, 2023"
"so @elonmusk
now that twitter blocks all requests that are not logged in, tweets can no longer be embedded in most chat apps
I'd strongly suggest reconsidering the UX+growth tradeoffs made here (take note how tiktok, youtube, etc, do not need this despite much higher b/w req!)"
----
@elonmusk
"This will be unlocked shortly. Per my earlier post, drastic & immediate action was necessary due to EXTREME levels of data scraping.
Almost every company doing AI, from startups to some of the biggest corporations on Earth, was scraping vast amounts of data.
It is rather galling to have to bring large numbers of servers online on an emergency basis just to facilitate some AI startup’s outrageous valuation."
It's amusing that anyone takes anything Elon says seriously. At this point the "free speech absolutist" has about as much credibility as an orange reality TV star.
good riddance it is a hell hole of people promoting stuff + conspiracy theorists and manipulators. it differentiates itself as "the shitshow social network".
seems like a great way to prevent view botting now that they are a media platform, also better value for their advertisers to use realistic statistics.
These services have the following (non-exhaustive) list of problems:
- They are hard to use for regular people due to lack of modern and intuitive clients.
- They are somewhat hard to discover and learn. For example, browsers don't indicate the presence of RSS feeds without plugins anymore.
- Security and encryption are an after-thought, if any
Almost all of the above are due to the stagnation of their development (protocols and clients) due to emergence of easy-to-use, but centralized alternatives. They are not good modern options as they are now. But they are good models to build more modern alternatives on.
Exactly this, I’m happy of what’s happening with twitter and Reddit and the likes, maybe it’s the reality slap the users needed to get back to smaller communities.
Several hundred organizations (maybe more) were scraping Twitter data extremely aggressively, to the point where it was affecting the real user experience.
What should we do to stop that? I’m open to ideas.
I always curse whenever someone posts "news" from twitter, I pretty much just ignore them already. I've never had a twit account, and don't intend to get one, particularly just to see HN posts from poorly chosen sources.
Much like paywalled sites, can we please stop posting twit links now?
This feels a little like the shittiest restaurant in town raising its prices. I have an account, and I wouldn't even bother logging in at this point. Why bother? The Twitter experience is so devotedly wretched that whatever I'd get from the tweet I want to see is outweighed by everything I have to wade through to see it.
There was a point when Twitter was good enough that maybe they could have pulled something like this and gotten away with it. At this point, I think all this will do is hasten their irrelevancy.
Centralisation vs decentralisation in tech is pretty much irrelevant.
What is relevant is governance. We allow billionaires and venture capitalists to govern a commons that we all rely on. Surprise surprise, it isn't going well.
The solution is not to have (difficult to scale) federated alternatives. The solution is collective ownership.
Imagine for a moment that the multinationals that are increasingly in charge of our lives were owned by their customers. Imagine they had a fair electoral system, reflecting the variety of those users, limiting them to one person, one vote, and that their constitutions were designed to guarantee the rights of minorities.
The journey that most countries went on through the 20th and 21st centuries, in other words.
Tech giants and other multinationals are a different kind of beast, because they govern a little slice of our lives instead of having carte blanche. But it is not beyond the realm of possibility for democratically operated multinationals to exist. It will be hard to do, but IMO, that approach has a bright future because non-techies can grasp it and participate in it more easily, and that is one less barrier to a runaway network effect than the fediverse has.
Can you not have both? Each federated instance costs money to upkeep. Some instances could elect for collective ownership or even elect to donate for develop (probably this needs to be carefully considered to deter corporate ownership). I like your idea but I think there needs to be an interim step and for now, maybe that's federation. Maybe we'll get to the place you speak of... one day.
We won't get there while people would rather rely on doing a bit of systems administration and hoping a developer can pay the bills. Not without strictly ideologically motivated admins and devs.
Distributed power takes more effort. Of course people naturally trend towards lazy over the generations because it's easier and more efficient at the cost of everything it was initially supposed to be. And now we are where we are: executive branch agencies legislating.
That's why we shouldn't optimize everything, the longer I live the more I understand that overoptimization is the root of all evil. We should analyse what we are doing and how we are changing things in the long term, monitor the situation and adjust accordingly. Otherwise our systems will find a local optimum that benefit the most powerful groups. Happens in all aspects of life, modern capitalism being the prime example.
It's that old tradeoff - convenience vs. single point of failure. Unfortunately, we're getting to see now what that single point of failure does to us. A big chunk of the open web is winking out of existence at this very moment.
There is a failure of technology too. The internet is distributed, sure, but the server-client architecture puts all the operational burden on the server. The expectation that everyone will run their own internet exposed instance of any thing is still simply not feasible, even today. The operational complexity of security, availability, monitoring etc are unmanageable even for technical users. Back when smaller forums were popular, hearing of a forum getting hacked was pretty much the norm. They get hacked, they go down for few days, they come back from a backup losing few days or hours of data, and on to the next vbulletin. Phpbb, nuke, or whatever vulnerability/hack. There doesn’t yet exist a distributed system that can replace something like facebook, twitter, Reddit, YouTube, TikTok, instagram, or even WhatsApp without a significant operational burden or added complexity.
It’s also not a very interesting problem to solve because of the type of cliffs you will run into due to precisely how the “internet works”
Doesn't come as a surprise when you look at how openly hostile the open source community still is to prioritizing user experiences and supporting tech-illiterate users in general.
FOSS, fediverse, IPFS all had their chance, and they blew it. Corporations were the ones who opened up the internet to the 99% of people who would otherwise never have been there at all, and now they want to collect their cut.
To be completely fair, FOSS' marketing budget is orders of magnitude smaller than these corporation's budgets. Not to say that you're wrong but I suspect that's more like a drop in the bucket compared to marketing.
Even now, these federated sites on the rise have technicial growing pains. And those will probably take years to get through until it's to a point where everyone can use it with little friction.
Twitter made a convenient, easy to use, centralized (which is an absolute positive for user experience), social media product that attracted people, by their own free will. The number of people using a social media service amplifies its "usefulness", so the more people, the stronger it attracts new users.
We didn't put the internet in the hands of these corporations. We walked over and sat in their, easy to use, hands.
The internet was conceived as a democratic haven, a realm where every individual had the potential to influence and shape their digital experience. However, a pervasive dip in technological literacy and a rising dependency on heavily-guided online pathways has begun to shift this balance. If this trend persists, corporations will continue to maintain their overarching dominion.
A dynamic, user-driven community still thrives in the vast expanse of the digital world, yet it lies hidden beyond the towering edifices of corporate-controlled structures. Discovering these spaces has become an increasingly formidable task, as the infusion of corporate social content into journalistic and blogging platforms perpetuates the mirage that such networks are all that exist.
Each colossal tech corporation we see today began its journey as a modest, affable endeavor. As these projects expanded with their burgeoning popularity, users neglected to challenge the escalating influence and control these companies wielded.
Nitter was merely an alternative facade to Twitter. Despite offering an ad-free environment, it lacked substantial advantages as the underlying platform remained the same - Twitter.
However, the digital realm is not void of choices. Federated social media is emerging as a profound alternative. Yet, a majority of those voicing concerns about corporate social media seem to dismiss options like Mastodon. This is primarily due to their increased technological demands and people's comfort in having a corporation guide their online journey.
The power to reshape your digital footprint rests in your hands. You can sever ties with your corporate social media accounts. You can choose to eschew media that incessantly embeds corporate social media content. You can advocate for an internet not ruled by corporate influence. All it requires is the willingness to venture beyond the realm of comfort.
> The internet was conceived as a democratic haven, a realm where every individual had the potential to influence and shape their digital experience.
I have a hard time reconciling this perspective with history. Were any of these ideals present among the people/organizations responsible for the internet and the Web at the time that they were being developed? Or is sentiment like yours something that people adopted later on?
I was speaking more to the ethos that arose as the internet was opened up to the public and began to evolve in the late 20th century. You are correct that this is a far cry from its initial conception as a military communications network (ARPANET).
The internet was conceived as a DARPA concept of reliable government communications in the face of unreliable transport, among many other research interests. For most of its early existence (through at least the NSFnet incarnation in the US), it was the private preserve of academic, government and military users, along with some of the corporations that supported them and commercial use beyond supporting projects was prohibited (e.g. you couldn't use it for advertising). It was far from a 'Democratic haven'. There were epic flamewars over 'do we let any more commercial content in our private backyard?' and 'why would we let regular people in?'.
However, a pervasive dip in technological literacy...
Right...it's bad we let the proles into utopia. So much for 'democratic havens'.
If you can't get the basic background right, it really damages the credibility of the rest of the screed (which I mostly agree with).
We the people were inactive & didn't figure out how to weave together our individual & community sites to create a compelling multi-party space.
Or we could try to create alternative centralized but non-corporate systems. Not sure what other options there are.
I don't like where we are either. But new power has to be created. Hard work of figuring out protocols to converse across & usefully home our content/words on is sort of just beginning.
"The internet" isn't in their hands, the "Pop Web" (eg, pop music) is. Plenty of other internet out there, it's just time for people to start paying attention to it again.
At university I was using JANET, and in some ways it was better than what we have now.
I don't think they'd have ever bothered inventing privacy violating trackers A/B testing (though if I'm wrong this is the best place to assert wildly and be quickly corrected).
You said it would be nothing without tech companies.
Without tech companies, it was still immensely useful.
Apps on iPhones? Great, but the internet doesn't need them to be hugely culturally and socially important — and I'm saying that as an iPhone app developer since before the first iPad came out.
That's a false dichotomy. Government-regulated doesn't mean government-run. I wish we had laws in place that would prevent Facebook/Apple/Google/Twitter monopolies/walled gardens from happening
I got banned from Twitter for putting Elons image as my profile pic and tweeting a friend asking if he wanted a job. It was a dumb joke but I got banned
In the email, they said “Note that if you attempt to evade a permanent suspension by creating new accounts, we will suspend your new accounts.”
So now I’m 100% banned from twitter if I follow the rules.
Why is so terrible to just open an account? what a drama
you're using a service that costs money to run.
Everyone here likes to be highly paid but keep complaining for those things. maybe I'm missing something here.
Use temp email, create an account and that's it.
If that's the way they (twitter in this case) wanted it, they should have started it that way. May be then, governments and individuals wouldn't have started sharing important information on a platform that requires their audience to forgo their anonymity.
Because if twitter decides that your email (address) is too temp, they might ask you for a phone number. And burner phones without (or with low hurdle) registration / verification aren't a thing everywhere.
You can blame this all you want on evil social media corporations, but the reality is AI companies scraping public conversations to feed LLMs are the current reason for walls being erected around every single garden. Facebook, Instagram, Twitter, Reddit, LinkedIn.. all heading toward full walled garden mode to prevent scrapers from repurposing data and profiting off their systems.
Federated systems are a nice idea, but they're not funded and will crumble under the same pressure until they too go into private mode. It's simply not a financially sound decision to run an open node that is continually harvested by corporations seeking to profit off the conversations occurring on your platforms.
AI companies is a stupid argument. If the AI company operates legitimately, then TOS prohibiting using the content for LLM training purposes would be enough. If the AI company doesn’t want to play ball then restricting public access won’t stop them, they’ll just register accounts en-masse and scrape that way.
Twitter has been slow since Musk took over and fired all of the competent devops people and then shut down most of the data centers. It's reasonable to assume that he's either been lied to or is lying about the cause of this.
Assuming social media companies are profitable via their normal services, then how they are hurt by downstream AI companies squeezing out a bit of leftover value? Because it feels like me being mad because I find out Jiffy Lube is making money reselling the used oil from my oil changes without giving me a cut.
I think it's a mistake to block third party providers from profiting from their service. First of all the hypocrisy in that all of these large companies exist because of massively profiting off of mostly uncompensated user-created content. Second, this drive toward relentlessly monetizing every aspect of your company's business is how we get degraded services like Microsoft putting ads in their search bar. It's one thing if a downstream OEM does it, I can just use an alternative OEM that doesn't shovelware the crap out of their product. But when the primary provider does it, then their service is permanently borked and eventually becomes unusable. So if the idea of blocking scrapers is because the goal is to eventually provide their own shitty AI services, I think Twitter et al are just going to end up killing their own geese -- making their own services unusable out of greed.
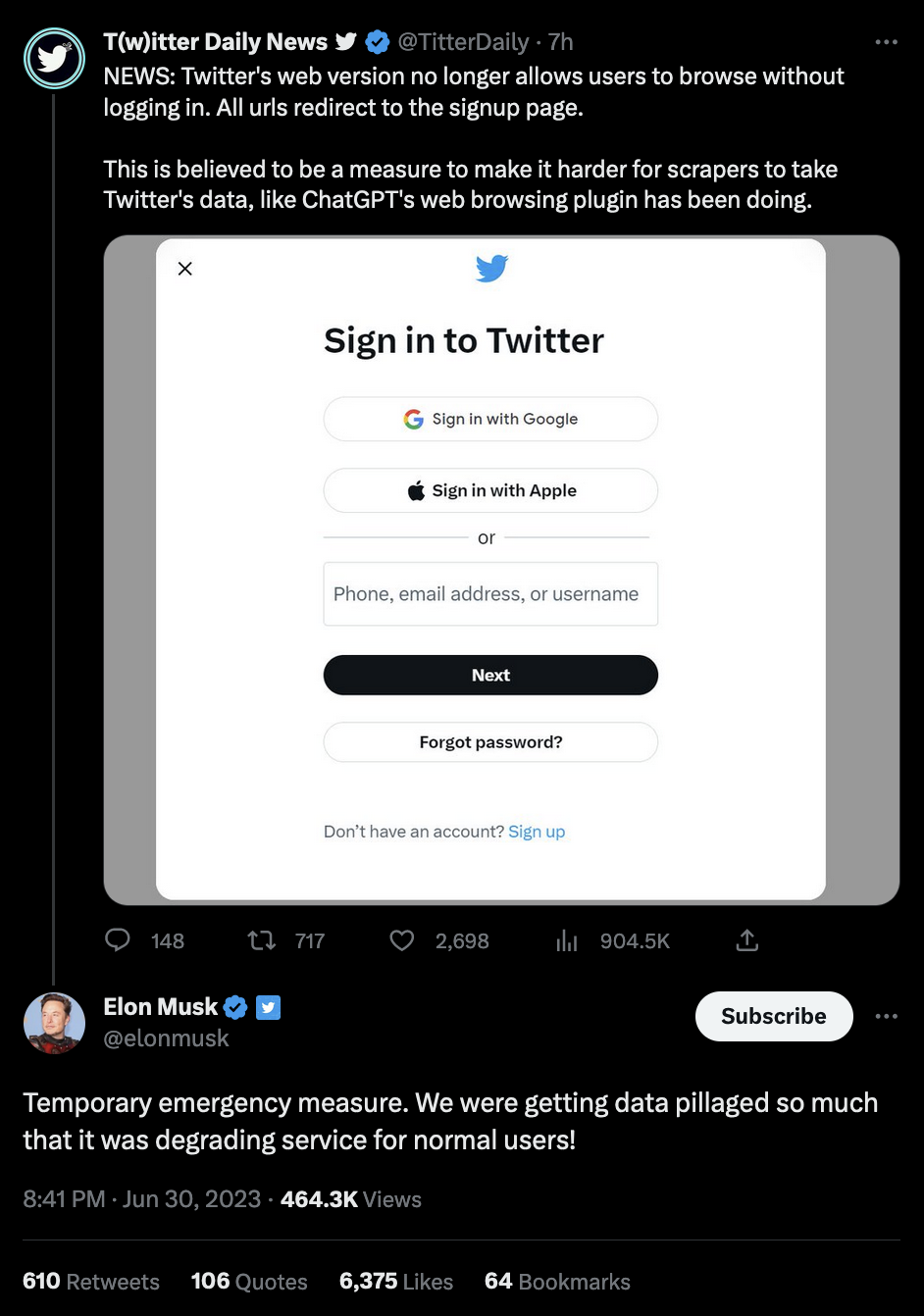{kind=link}
"This will be unlocked shortly. Per my earlier post, drastic & immediate action was necessary due to EXTREME levels of data scraping.
Almost every company doing AI, from startups to some of the biggest corporations on Earth, was scraping vast amounts of data.
It is rather galling to have to bring large numbers of servers online on an emergency basis just to facilitate some AI startup’s outrageous valuation."